Comprehensive View of Optimistic Locking
Importance of Locking in Databases
Locking in databases serves a fundamental purpose: it preserves the integrity of data during concurrent transactions. This means when multiple users or processes are reading and modifying the database, locks help maintain accuracy and consistency. The importance of locking can be seen particularly in preventing issues such as dirty reads, non-repeatable reads, and phantom reads – all typical concurrent access problems. Moreover, locking mechanisms ensure that the data transaction it is working on does not get altered by another transaction before it completes, which rules out lost updates and offers a robust version control.
How Does Optimistic Locking Work?
Optimistic locking prevents scenarios where two users try to write to the same record and one transaction ends up overwritting the other one.
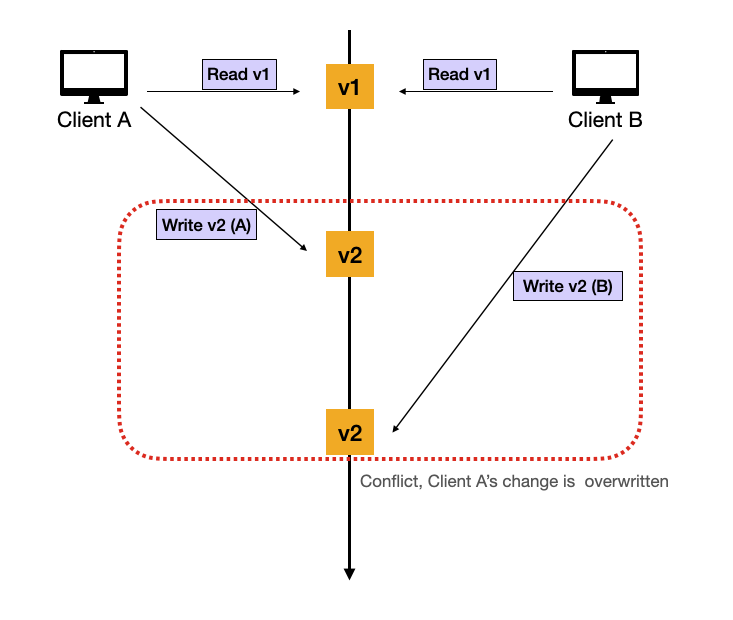

Optimistic locking is a concurrency control method that, unlike pessimistic locking, assumes a low chance of conflict and therefore does not lock the data while reading. Instead, it tracks versions of a persistent object. Here's how the process unfolds:
- Each record contains a version field, which could be a timestamp or an incrementing number. This version represents the state of the record at the time of reading.
- Upon an update attempt, the application checks the current version with the original version.
- If the versions match, it means the record has not been modified by another transaction. The update proceeds, and the version field is incremented.
- In case of a version conflict, the application throws an optimistic locking exception, signaling a failed update due to concurrent modifications.
To illustrate:
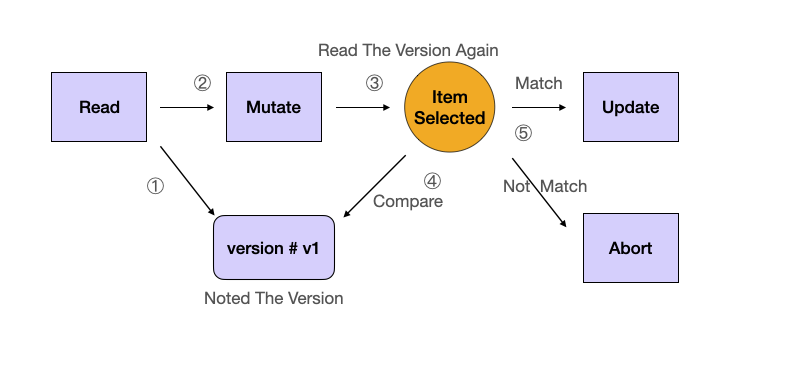
This illustration represents the optimistic locking cycle. Initially, a user reads the data, noting the version. When ready to update, the application performs a version check. If there's a version match, the update goes through, and the version increments. Otherwise, the process is aborted, and the user must resolve the conflict.
Optimistic locking is especially useful for applications dealing with a large number of reads, and fewer updates, as it reduces the overhead of managing locks and can enhance performance. The method shines in client-server applications or services employing connection pooling, where maintaining a stateful connection for each user can be impractical.
Optimistic locking significantly reduces the risk of record locking issues, which can cause applications to become unresponsive. It also supports less-strict isolation levels in transactions, which can be less restrictive on the database and allow for better concurrency. However, it requires careful design to handle conflict resolution effectively, ensuring the application can gracefully handle optimistic locking exceptions and resolve them with minimal disruption to user experience.
Contrast Between Optimistic and Pessimistic Locking
Operational Differences: Optimistic Locking VS Pessimistic Locking
At the core, optimistic and pessimistic locking represent contrasting strategies for handling transactions that modify data. Pessimistic locking takes a conservative approach, locking the records upon the first read with the assumption that a conflict is likely to occur. This prevents any other transactions from modifying the data until the lock is released. In contrast, optimistic locking forgoes immediate locking for a more liberal approach. It allows multiple concurrent reads and only checks for version conflicts at update time. This difference in approach can lead to variations in system performance and user experience:
-
Pessimistic Locking:
- Locks data immediately to prevent other users from modifying it.
- Can lead to deadlocks where two or more operations wait indefinitely for each other to release locks.
- May cause delays due to extensive lock management.
- Is more suitable when updates are frequent and the chance for data conflicts is high.
-
Optimistic Locking:
- Allows concurrent reads with no immediate locking, reducing initial delays.
- Performs a version check before any update - if data is altered by another transaction, an error is raised.
- Can improve performance due to reduced locking overhead.
- Is ideal for systems with fewer updates and a lower risk of data conflict.
These operational differences underscore why understanding the behavior of your system under concurrent access is critical in choosing the right locking mechanism.
Choosing the Right Locking Strategy for Your Application
When it comes to selecting a locking strategy for your application, it's about matching the method to your specific needs. Here’s how you can approach the decision:
- Assess the frequency of concurrent updates: If your application is update-intensive, the certainty of pessimistic locking may trump the performance gains of an optimistic strategy.
- Consider user experience: Pessimistic locking can lead to frustration due to waiting times, while failed updates with optimistic locking might confuse users without proper handling.
- Examine system performance: Optimistic locking can offer better throughput in read-heavy systems.
Ultimately, the choice hinges on striking a balance between data integrity, system performance, and user satisfaction. By carefully weighing the pros and cons, you can leverage the locking mechanism that aligns with your application’s functionality and user expectations. It's not just about preventing data conflicts but doing so in a way that maintains system efficiency and users' workflow intact.
Advantages and Drawbacks of Optimistic Locking
Benefits of Implementing Optimistic Locking
Optimistic locking brings multiple advantages to the table, particularly in scenarios with high read volume and fewer conflicting updates:
- Improved Performance: Without the need to manage locks on every operation, systems can execute reads and writes more swiftly, leading to better overall application performance.
- Scalability: This model can handle a growing number of concurrent users with ease, making it a go-to choice for applications expecting to scale.
- User Experience: By eliminating wait times caused by locked records, users can interact with the system without unnecessary delay.
- Simplified Design: In systems with less-strict isolation requirements, optimistic locking simplifies transaction management by avoiding the complexity of lock management.
When utilized correctly, optimistic locking ensures that data integrity is not compromised, despite removing the immediate locking bottleneck, thus offering a lightweight and responsive approach to transaction management.
Potential Challenges and Solutions Connected to Optimistic Locking
However, optimistic locking is not free from challenges:
- Conflict Handling: When conflicts occur, users may experience errors when trying to save their work, which could lead to frustration and the need for additional conflict resolution logic.
- Data Loss: There's a risk of data being overwritten if a user submits an update without realizing another update has taken place since their initial read.
To address these challenges, implement these solutions:
- User Notifications: Inform users immediately when a conflict arises, possibly offering the ability to merge changes or retry an action.
- Version History: Maintain a history of record versions to enable data recovery or merge operations.
- Efficient Retries: Implement a smart retry mechanism that reduces the need for user intervention and enhances the chances of a successful update.
Even with competent solutions in place, it's crucial to ensure that the advantages align with the specific context and needs of your application. The goal is to maintain proactivity in reducing conflict potential and to ensure that when it does happen, the system is designed to resolve issues quickly and effectively, with minimal user disruption.
Implementing Optimistic Locking
Implementing Optimistic Locking Using OUTPUT/RETURNING or a Separate SELECT Query
Optimistic locking typically involves including a version field in the database table. When updating a record, the version number is checked and incremented. Here are two ways to implement this in SQL:
Using OUTPUT/RETURNING (For SQL Server/PostgreSQL):
UPDATE YourTable
SET Column1 = 'NewValue', Version = Version + 1
OUTPUT INSERTED.*
WHERE YourID = 1 AND Version = @CurrentVersion;Using a Separate SELECT Query:
SELECT Version FROM YourTable WHERE YourID = 1;
UPDATE YourTable
SET Column1 = 'NewValue', Version = Version + 1
WHERE YourID = 1 AND Version = @CurrentVersion;If @CurrentVersion matches the version in the table, the update goes through, and you get the new state of the row. If the versions don't match, it indicates someone else has updated the record, and you can handle the conflict accordingly.
Usage of WHERE Clause in Optimistic Locking
The WHERE clause is vital in optimistic locking, ensuring the record hasn't changed between the read and update operations. Here's a SQL example of utilizing a WHERE clause for optimistic locking:
UPDATE YourTable
SET Column1 = 'NewValue', Version = Version + 1
WHERE YourID = 1 AND Version = @CurrentVersion;With this WHERE clause, an update is only successful if the record's current version matches @CurrentVersion. If the record has been updated by someone else, the version won’t match, and the update will not affect any rows.
Here's the full application code using Python:
import psycopg2
# Function to read a product's data (including version)
def read_product(cursor, product_id):
cursor.execute("SELECT id, name, quantity, version FROM products WHERE id = %s", (product_id,))
return cursor.fetchone()
# Function to update a product's quantity with optimistic locking
def update_product_quantity(conn, cursor, product_id, new_quantity, original_version):
cursor.execute("""
UPDATE products
SET quantity = %s, version = version + 1
WHERE id = %s AND version = %s
RETURNING version;
""", (new_quantity, product_id, original_version))
updated_version = cursor.fetchone()
if updated_version is None:
# The update did not affect any row, indicating a version conflict
conn.rollback() # Rollback the transaction to maintain atomicity
return False, "Conflict detected: the product was modified by another transaction."
else:
conn.commit() # Commit the update
return True, updated_version[0]
# Example usage
conn = psycopg2.connect(
dbname='yourdbname', user='youruser', password='yourpassword', host='localhost'
)
cursor = conn.cursor()
# Example product_id and new_quantity
product_id = 1
new_quantity = 10
# Step 1: Read the product (including its version)
product = read_product(cursor, product_id)
if product:
product_id, name, quantity, original_version = product
# Step 2: Attempt to update the product's quantity
success, result = update_product_quantity(conn, cursor, product_id, new_quantity, original_version)
if success:
print(f"Update successful. New version is {result}.")
else:
print(f"Update failed: {result}")
else:
print("Product not found.")
# Close the connection
cursor.close()
conn.close()
Case Study: Spring Data JPA and Optimistic Locking
In Java, using Spring Data JPA, optimistic locking can be implemented with a @Version annotation:
@Entity
public class YourEntity {
@Id
private Long id;
@Version
private Integer version;
// other fields and methods
}Then, the repository takes care of checking and incrementing the version number during an update:
YourEntity entity = repository.findOne(id);
entity.setColumn1("NewValue");
repository.save(entity);Spring Data JPA handles the version check and increments automatically. An OptimisticLockingFailureException is thrown if a conflict occurs.
Optimistic Locking with SQL Implementation
When using raw SQL for optimistic locking, the implementation is manual yet straightforward:
-- Fetching the current version
SELECT Version INTO @CurrentVersion FROM YourTable WHERE YourID = 1;
-- Attempting to update with version check
UPDATE YourTable
SET Column1 = 'NewValue', Version = @CurrentVersion + 1
WHERE YourID = 1 AND Version = @CurrentVersion;
-- Checking if the update was successful
IF @@ROWCOUNT = 0
RAISERROR ('Update failed due to concurrent modification', 16, 1);By executing these statements, you manually handle the version checking and incrementing. The IF statement at the end checks if the row was actually updated, indicating whether a concurrent modification took place. If no rows were updated, it raises an error for the application to handle.
Advanced Concepts in Optimistic Locking
Phases of Optimistic Concurrency Control
Optimistic concurrency control rests on a three-phase process model, designed to ensure integrity without the overhead of traditional locking. These phases are:
- Begin: A transaction starts and records the initial version of data being accessed.
- Validation: Upon the transaction’s commit, the system checks if the data versions are unaltered from the start.
- Commit/Rollback: If the data is unchanged, the transaction commits, updating the version. If the data version has changed (indicating a conflict), the transaction rolls back.
This approach allows multiple transactions to proceed in parallel, significantly enhancing throughput and reducing resource contention in environments with high concurrency.
Understanding Version Locking Policies
With optimistic locking, the concept of a "locking policy" revolves around how versions are tracked and validated. Common strategies include:
- Version Number: A simple incrementing counter ensures that an update reflects the latest version.
- Timestamp: A timestamp can track the exact time changes occurred, requiring a "newer" timestamp to overwrite data.
- Checksums: A calculated value based on the contents of a record, ensuring data integrity at a granular level.
Each policy has implications for system design and must align with the specific requirements of the application to be effective. Selecting the right version locking policy is a critical step in successfully implementing optimistic concurrency control.
Optimistic Lock Management: Disabling and Enabling Locks
Managing when and how optimistic locks are engaged is key to fine-tuning performance and ensuring flexibility. Developers have several methods at their disposal to disable or enable optimistic locks dynamically:
- In scenarios requiring bulk updating or high-speed data ingestion, temporarily disabling optimistic locks can increase efficiency.
- When proceeding with sensitive operations where data integrity is paramount, enabling optimistic locks provides a safety net against concurrent modifications.
To toggle locks, developers might use a specific API or code constructs to skip or enforce version checks, akin to this SQL example:
-- Disabling locks during bulk operation
SET session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
BULK INSERT YourTable FROM 'source.csv';
-- Enabling locks after operation completion
SET session TRANSACTION ISOLATION LEVEL REPEATABLE READ;By adjusting the transaction isolation level, the code snippet above manipulates the locking granularity, showcasing the application's ability to modify its lock management strategy dynamically. It's a powerful capability, yet one that requires discernment to avoid compromising data integrity.
Key Takeaways from Optimistic Locking
When reflecting on the concepts and details of optimistic locking, there are pivotal insights that software engineers should carry forward:
-
Optimistic Locking Efficiency: Optimistic locking is less resource-intensive than pessimistic locking, making it well-suited for systems with a high volume of reads and low incidence of write-write conflicts. Its non-locking read operations often mean better system performance and user experiences, especially in scalable, multi-user environments.
-
Version Control is Critical: At the heart of optimistic locking lies version control. Whether using version numbers, timestamps, or checksums, maintaining a versioning scheme is crucial to detecting when data has been modified during the course of a transaction.
-
Handling Concurrent Transactions: While optimistic locking reduces the likelihood of performance bottlenecks, it does require solid strategies for managing data conflicts. Implementing clean, user-friendly mechanisms to resolve update conflicts is necessary for maintaining data integrity and a smooth user experience.
-
Dynamic Lock Management: Knowing when to enable or disable optimistic locks based on the transaction’s nature is an advanced technique that can further optimize performance. However, it should be done with caution to prevent risking data integrity.
Engineers should consider these takeaways as guiding principles, not just for implementing robust concurrency control but also for designing responsive and user-friendly applications. With these principles in mind, optimistic locking can be a powerful tool in a developer's arsenal, offering a blend of performance, scalability, and reliability.
FAQs Pertaining to Optimistic Locking
When is Optimistic Locking the Best Option?
Optimistic locking shines in scenarios where your application has a high volume of read operations but update conflicts are relatively rare. This typically aligns with systems that have multiple concurrent users who mostly view data rather than modify it, as in the case of reporting tools or informational platforms. It's also an excellent choice when performance and scalability are primary concerns, and the overhead of managing numerous locks from pessimistic locking could result in bottlenecks.
How to Handle Conflicts in Optimistic Locking?
Resolving conflicts in optimistic locking requires a strategy that emphasizes user communication and graceful recovery. Generally, when a conflict is detected, the system should:
- Notify the user about the update conflict, providing clear information that another transaction has altered the data.
- Offer options to the user, such as retrying the transaction, merging their changes with the new version, or discarding their update.
- Ensure that the retry mechanism is efficient and minimally intrusive, ideally integrating conflict resolution within the user interface flow.
What Role do Locking Strategies Play in Large-Scale Applications?
In large-scale applications, locking strategies play a crucial role in maintaining data integrity, ensuring system responsiveness, and facilitating smooth user experiences during high loads and across distributed systems. The right locking strategy can prevent data corruption from concurrent transactions and reduce the occurrence of deadlocks, which can be critical in high-stakes environments like financial systems or real-time data processing services. Optimistic locking, specifically, allows for a more read-optimized experience, keeping the application swift and more scalable by minimizing performance hits from aggressive lock management.