
A user books a flight, reserves a hotel, and rents a car. Three separate services. Three separate databases. The flight booking succeeds. The hotel reservation fails. The flight is booked but the hotel isn't. The user has an incomplete trip.
This is a distributed transaction problem. Multiple services must either all succeed or all fail. Without coordination, partial failures leave the system in an inconsistent state.
When You Need Distributed Transactions
Previous articles covered consistency models—how systems handle data visibility across replicas. Distributed transactions address a different problem: multi-step operations that span services.
In a monolithic application, you wrap operations in a database transaction:
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;Either both updates succeed or both rollback. The database guarantees atomicity.
But microservices architectures use one database per service. The Order Service has its own database. The Payment Service has its own. The Inventory Service has its own. A single database transaction cannot span them.
When a checkout request arrives, you must:
- Create order in Order Service
- Charge payment in Payment Service
- Decrement inventory in Inventory Service
All three must succeed or all must rollback. How do you coordinate this?
Two-Phase Commit (2PC)
Two-Phase Commit is a protocol for atomic commitment. It uses a coordinator to orchestrate the transaction across multiple participants (databases or services).
2PC works in two phases:
Phase 1: Prepare
The coordinator sends a "prepare" message to all participants. Each participant executes the transaction up to the point of commit, writes to its transaction log, and locks resources. But it doesn't commit yet.
If the participant can commit, it responds "yes." If it encounters an error, it responds "no" or times out.
The coordinator waits for all responses. If all participants vote "yes," proceed to phase 2. If any participant votes "no," abort.
Phase 2: Commit or Abort
If all participants voted "yes," the coordinator writes "commit" to its transaction log. This is the commit point. The decision is now irrevocable. The coordinator sends "commit" to all participants.
If any participant voted "no," the coordinator sends "abort" to all participants.
Participants execute the decision. If they voted "yes," they must honor the coordinator's decision, even if it requires waiting for the coordinator to recover from a crash.
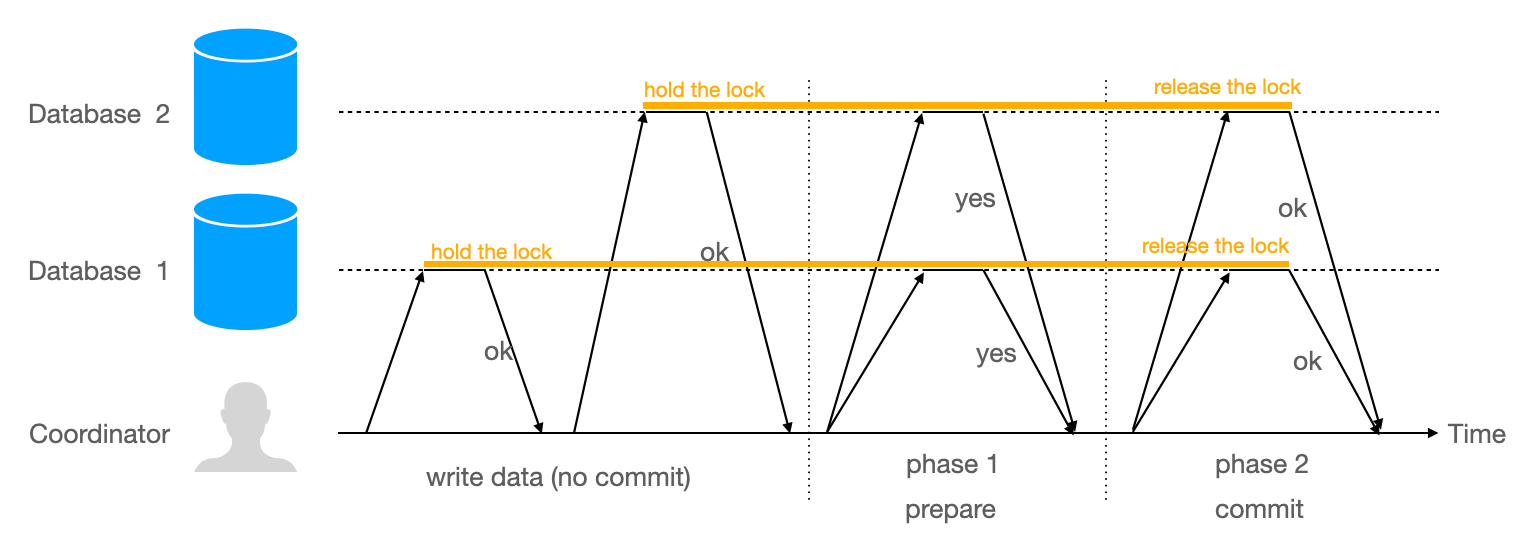

2PC provides atomicity: either all participants commit or all abort. This is the same guarantee as single-database transactions.
Problems with 2PC
2PC sounds correct. But it has serious practical problems that make it unsuitable for many distributed systems.
Blocking
Once a participant votes "yes," it's blocked waiting for the coordinator's decision. It has locked resources. It cannot release them until the coordinator says commit or abort.
If the coordinator crashes after collecting votes but before sending the decision, participants are stuck. They cannot commit (coordinator might have decided abort). They cannot abort (coordinator might have decided commit). They must wait for the coordinator to recover.
This blocking violates availability. A coordinator failure takes down the entire transaction system.
Performance
2PC requires two rounds of network communication: prepare then commit. Each round waits for the slowest participant. In a geo-distributed system, this adds hundreds of milliseconds.
Participants hold locks during both phases. This reduces concurrency. Other transactions wait for locks to release.
2PC adds significant latency compared to local transactions due to extra network round trips and extended lock holding. This cost is acceptable for some systems (financial transfers requiring perfect consistency). But most web services cannot afford this latency.
Coordinator as Single Point of Failure
The coordinator is a single point of failure. You can replicate the coordinator using consensus algorithms like Raft or Paxos, but now you've added another layer of complexity and latency.
Traditional relational databases (MySQL, PostgreSQL, Oracle) support 2PC. But cloud databases often don't. DynamoDB doesn't support 2PC. Cassandra doesn't. Cloud Spanner uses 2PC for cross-partition transactions but relies on Paxos for replica agreement within each partition.
Saga Pattern
The Saga Pattern takes a different approach. Instead of making all services commit atomically, it uses compensating transactions to undo failures.

The name "Saga" comes from a concept in storytelling and gaming where events unfold sequentially. In Magic: The Gathering, Saga cards progress through chapters. Similarly, distributed sagas progress through transaction steps.
A saga is a sequence of local transactions. Each step commits immediately to its own database. If a step fails, the saga executes compensating transactions to undo previous steps.
Example: Book flight, reserve hotel, rent car.
Success path:
- Book flight → committed
- Reserve hotel → committed
- Rent car → committed
Failure path:
- Book flight → committed
- Reserve hotel → committed
- Rent car → fails
- Cancel hotel reservation (compensating transaction)
- Cancel flight booking (compensating transaction)
Each service defines a compensating transaction for its operation. Flight booking service provides a "cancel booking" endpoint. Hotel service provides "cancel reservation." When a saga step fails, the saga executor calls compensating transactions in reverse order.

Saga vs 2PC
2PC prevents partial failures. All services commit or all abort, coordinated by a single transaction. This requires that you control all participating services and they support the 2PC protocol. You cannot use 2PC with third-party services or external APIs that don't implement prepare/commit phases.
Saga accepts partial failures temporarily. Services commit individually. If a later step fails, compensate earlier steps. The system is inconsistent during compensation but eventually reaches a correct state. Sagas work with any service that exposes operations and compensations, including third-party APIs.
Sagas trade consistency for availability and flexibility. They don't require blocking or a heavyweight coordinator. They perform better and scale better. They work across organizational boundaries. But they require more complex application logic and compensating transactions.
Choreography vs Orchestration
Sagas can be implemented two ways: choreography or orchestration.
Choreography
Services communicate through events. No central coordinator.
- Order Service creates order, publishes "OrderCreated" event
- Payment Service listens, charges payment, publishes "PaymentCharged" event
- Inventory Service listens, decrements inventory, publishes "InventoryUpdated" event
If Payment fails, it publishes "PaymentFailed" event. Order Service listens and cancels the order.

Pros: Decentralized, no single point of failure, loosely coupled.
Cons: Hard to understand overall flow, difficult to debug, no central place to see saga state.
Orchestration
A central orchestrator coordinates the saga.
- Saga Orchestrator sends "charge payment" command to Payment Service
- Payment Service responds success/failure
- If success, orchestrator sends "decrement inventory" to Inventory Service
- If failure, orchestrator sends "cancel order" to Order Service

Pros: Clear flow, easy to monitor, centralized state management.
Cons: Orchestrator is a dependency (though not a single point of failure—it can be stateless and replicated).
For most systems, orchestration is simpler. Use choreography only if you need maximum decoupling or very high scale.
Avoiding Distributed Transactions
The best distributed transaction is the one you don't need. Before reaching for 2PC or Sagas, consider whether you can redesign to avoid the problem entirely.
Keep Related Data Together
If Order, Payment, and Inventory always change together, they might belong in the same service with one database. Microservices shouldn't be arbitrarily fine-grained.

A single Checkout Service can handle order creation, payment charging, and inventory decrement in one local transaction. No distributed coordination needed. The cost is reduced team autonomy—one team owns the entire checkout flow.
This is often the right choice. The industry over-corrected toward microservices. Many systems would be simpler as well-structured monoliths or "macroservices" with broader boundaries.
Accept Eventual Consistency
Most operations don't need atomicity. A user books a ride. You create the booking immediately. Payment processes asynchronously seconds later. If payment fails, you notify the user and cancel the ride.

The booking exists briefly without payment. That's acceptable. Users understand "payment processing." This is simpler than coordinating booking and payment atomically.
Ask: what's the actual business requirement? Often "all steps must succeed" really means "all steps must eventually succeed, and users must know the outcome." Eventual consistency satisfies that.
Asynchronous with Message Queues
Order Service writes the order to its database and publishes an event to Kafka. Payment Service consumes the event and charges payment in its local transaction. Inventory Service consumes and decrements stock.

Each service uses local transactions. No distributed transaction needed. If Payment fails, it publishes a failure event. Order Service listens and marks the order canceled.
This is the Saga pattern implemented via choreography, but framed as "avoiding synchronous coordination." It's reliable and scalable. The tradeoff is debugging—you trace through message logs instead of a single request.
Other Patterns
Outbox Pattern solves the dual-write problem when you need to atomically update a database and publish an event. Write both the entity change and an outbox event to the database in one transaction. A separate process reads the outbox table and publishes to the message broker. This ensures events are published reliably without distributed transactions.
TCC (Try-Confirm/Cancel) is an application-level alternative to 2PC. Each service exposes three operations: Try reserves resources, Confirm commits, Cancel rolls back. Popular in some Chinese tech companies but adds significant complexity to every service.
Choosing an Approach
The first question is whether you need distributed transactions at all. If you can consolidate related data into one service with local transactions, do that. If you can accept eventual consistency and notify users of outcomes, do that. If you can use message queues for asynchronous processing, do that. These approaches are simpler and more reliable than any distributed transaction pattern.
When you truly need distributed transactions, choose based on consistency requirements. Use 2PC when you need perfect consistency—financial systems that cannot tolerate any temporary inconsistency, inventory systems that must never oversell. You need control over all services and they must support 2PC. Latency requirements must be loose enough to absorb the extra round trips. You must accept reduced availability when the coordinator fails.
Most systems should use Sagas instead. Sagas work when you must coordinate across services with independent databases but can tolerate brief inconsistency. Availability and latency matter more than perfect consistency. You can design compensating transactions for your operations. The booking exists before payment completes. The payment charge happens before inventory updates. These temporary inconsistencies are acceptable because they resolve within seconds and users know the outcome.
Modern systems avoid distributed transactions when possible or use Sagas when necessary. The flexibility and performance outweigh the added complexity of compensation logic.
Interview Application
When asked about distributed transactions, first question whether you need them:
"For e-commerce checkout, we could split into Order, Payment, and Inventory services. But that creates distributed transaction problems. Let's consider a single Checkout Service that handles all three in one local transaction. If the team is small enough to own this, it's simpler."
If you must coordinate across services, explain the trade-off:
"If we need separate services, we'll use the Saga pattern with orchestration. The Order Service acts as coordinator. It calls Payment Service, then Inventory Service. If payment fails, we mark the order failed immediately. If inventory fails after payment succeeds, we issue a refund and cancel. The user sees the outcome and can retry."
"We could use 2PC for perfect consistency, but it adds 100-200ms latency and blocks resources during coordinator failures. Saga gives better availability. The system is briefly inconsistent—payment charged but inventory not yet updated—but that resolves within seconds."
"We log all saga steps for debugging. Each operation uses idempotency keys so retries are safe."
This shows you understand distributed transactions deeply enough to avoid them when possible, and choose the right pattern when necessary.