






MapReduce
HDFS
Distributed file system, you say? How does that work? Let's introduce HDFS.
HDFS, or the Hadoop Distributed File System, is a big part of the Hadoop ecosystem, which is all about dealing with huge amounts of data. Imagine you have a massive amount of data - so big that it doesn't fit on your computer or even a single server. HDFS comes to the rescue by allowing you to store and manage all that data across multiple computers, also known as nodes, in a distributed manner.
The main idea behind HDFS is to break up the large data into smaller chunks and distribute those chunks across different nodes in a cluster. This way, you're not relying on a single computer to store everything. Instead, you're spreading the data around, which makes it easier to handle and process.
HDFS also takes care of redundancy, which means it keeps multiple copies of your data on different nodes. This is super important because if one of the nodes goes down or has an issue, you don't want to lose any data. HDFS automatically makes sure you have backup copies, so you don't have to worry about data loss.
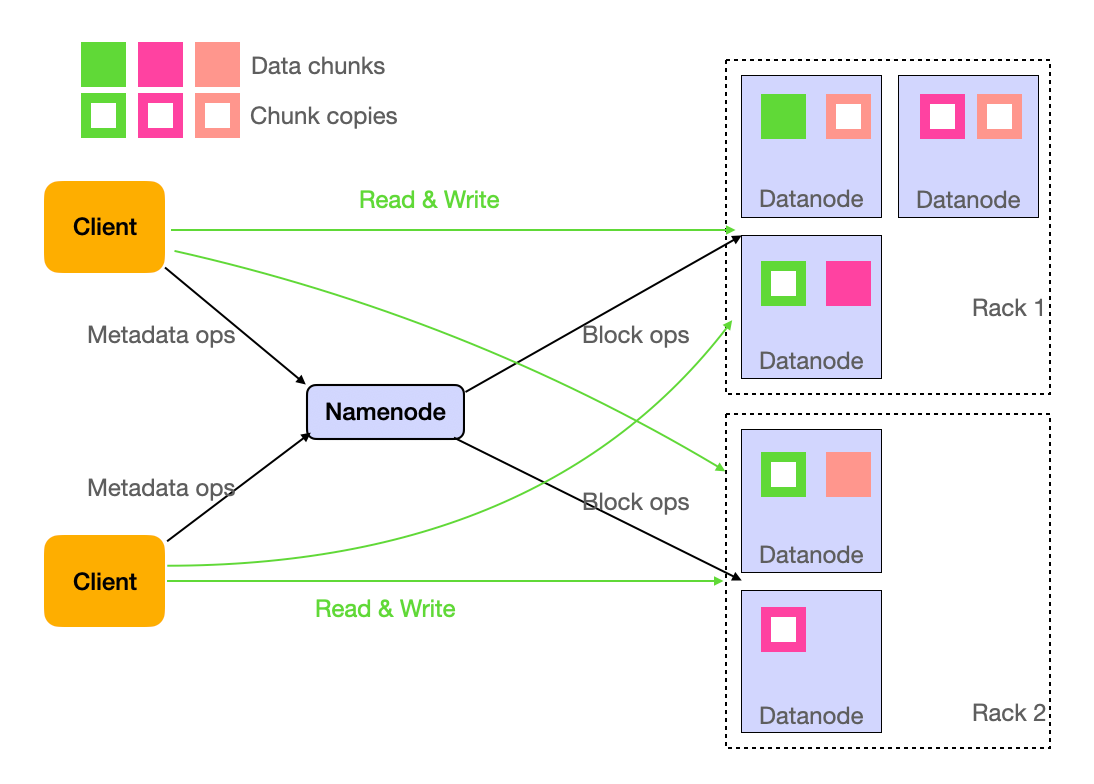

HDFS Architecture
The machines that store actual data are called DataNodes. A daemon process running on each machine, exposing a network service that allows other nodes to access files stored on that machine.
A central server called NameNode is like the control center that keeps track of all the data stored in the system. It's a special type of machine in the Hadoop cluster that manages the file system's metadata. Metadata is basically the information about your data, like the file names, their locations on the different nodes, permissions, and other details.
If a DataNode fails or becomes unavailable, the NameNode detects the issue and initiates the replication process to create additional copies of the affected data blocks. This ensures that the desired replication factor is maintained, and the data remains accessible even in the face of node failures.
Using the Unix analogy above, HDFS is our file system and MapReduce is the processing model (unix pipes). Hadoop (the framework) = HDFS (the file system) + MapReduce (the processing model).
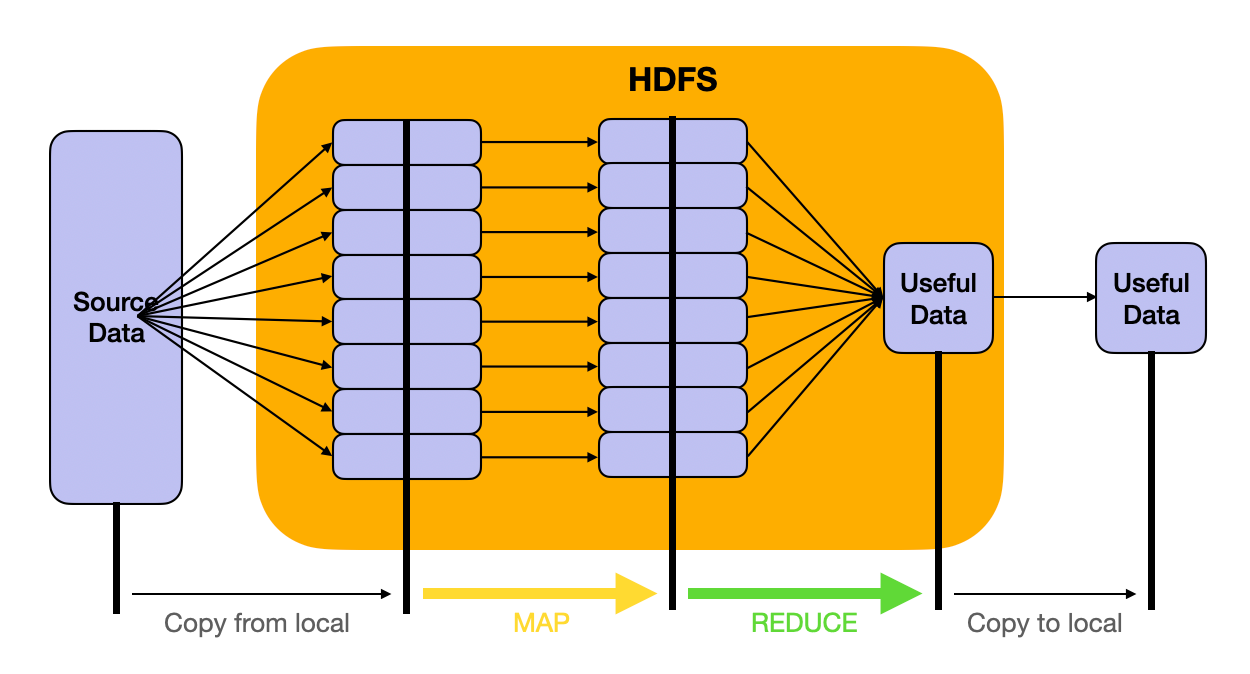
MapReduce computing model
MapReduce model
The MapReduce model consists of two primary functions: the Map function and the Reduce function.
- Map function (Mapper): The Map function processes the input data by dividing it into smaller chunks or key-value pairs. Each chunk is processed independently and in parallel by different worker nodes in the cluster. The output of the Map function is a set of intermediate key-value pairs. The
awkfrom the Unix example above is essentially a map function. The mapper function is called once for each input record - Reduce function (Reducer): The Reduce function takes the output of the Map function (the intermediate key-value pairs) and aggregates the values based on their keys. The Reduce function is also executed in parallel across the worker nodes in the cluster. The final output is a set of aggregated key-value pairs. The
uniqfrom the Unix example above is a reduce function.
Now you may ask what about the sort call between awk and uniq in the Unix example?
Between the mapper and the reducer, there is a default sort step that sorts all the key-value pairs produced by the mapper and sends the ones with the same keys to the same machine. This is often called the shuffle step. Here’s an illustration:
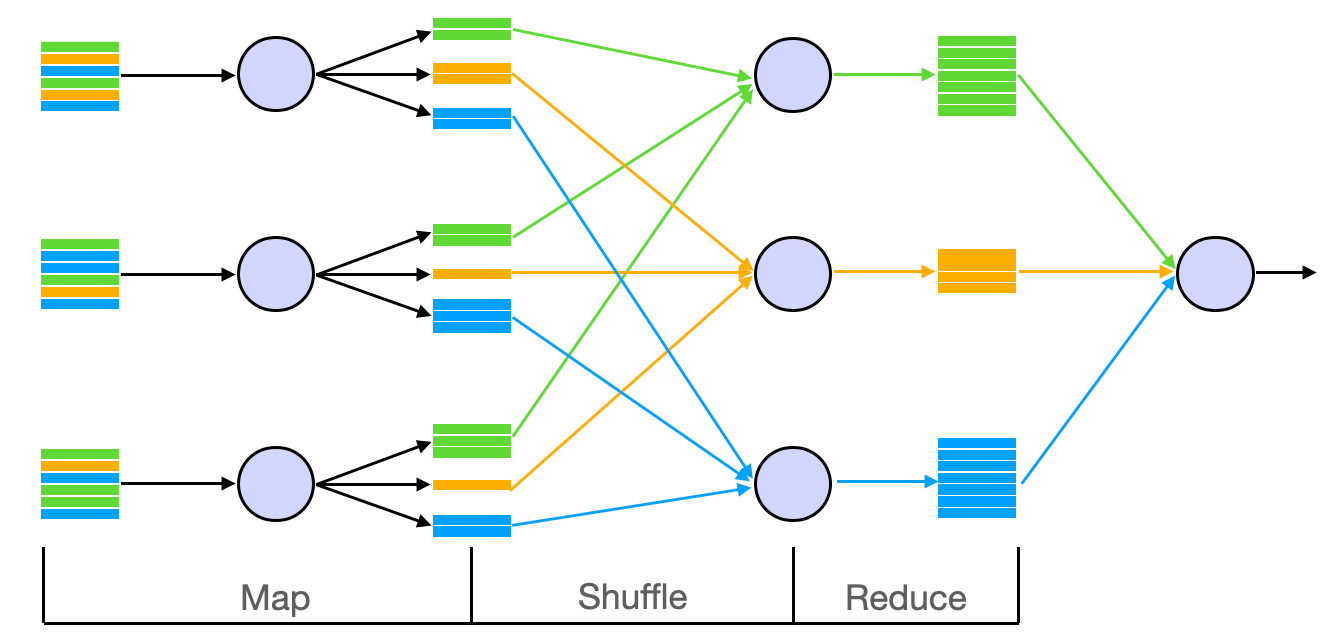
Shuffling in MapReduce
Here's another figure that demonstrates how data is processed on different machines. The dashed boxes represent these machines.
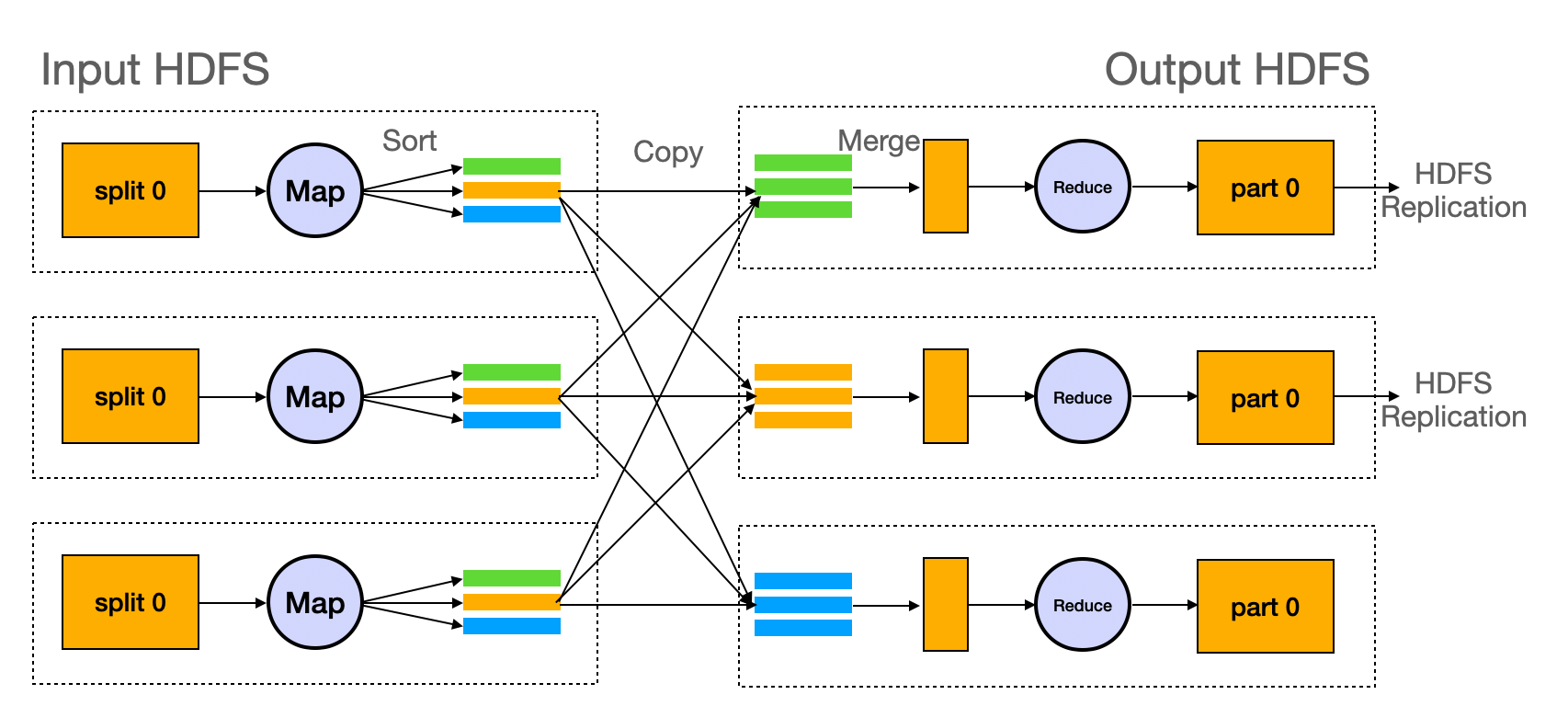
MapReduce on different machines
MapReduce demo
Now it’s hard to demonstrate HDFS and MapReduce in the browser environment since you’d need to set up a distributed system somewhere. However, we have an example using MongoDB just to demonstrate the programming model:
https://onecompiler.com/mongodb/3z694vyj6
In this example, we have a number of customer orders and we want to find the customers who spend the most and the amount they spent.
An order looks like this:
{ _id: 1, cust_id: "Ant O. Knee", ord_date: new Date("2020-03-01"), price: 25, items: [ { sku: "oranges", qty: 5, price: 2.5 }, { sku: "apples", qty: 5, price: 2.5 } ], status: "A" },The mapper emits the key-value pair (customer_id, price):
function() { emit(this.cust_id, this.price); }After the shuffle phase, all customers with the same customer_ids are collected to the same machine and we use the following reducer to find the sum:
function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
}Note that this is just an example to demonstrate the programming model. There isn’t a direct link between the MongoDB and HDFS. MongoDB simply offers the programming model like many NoSQL databases offer SQL query interface even though the underlying system is different.
MapReduce Workflow
MapReduce is cool, but a single MapReduce job can do very little. If we want to do more sophisticated tasks, we can chain multiple MapReduce jobs together into a workflow such that the output of one job becomes the input to the next job.
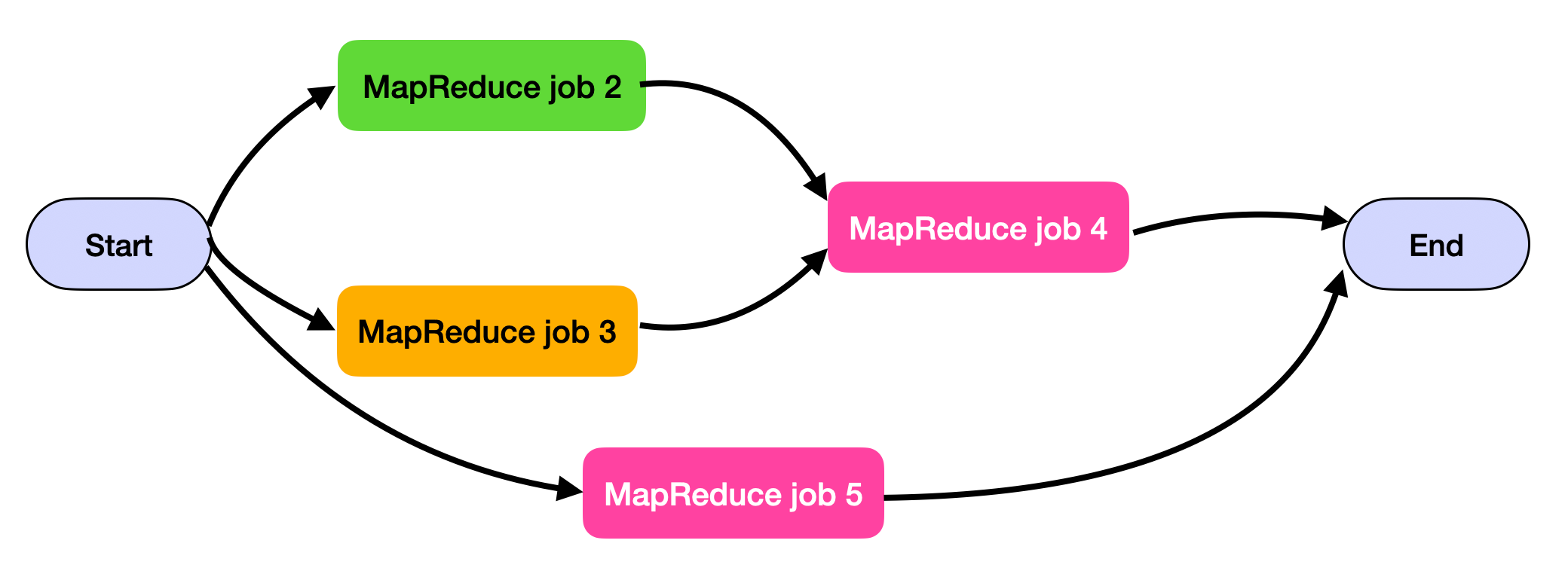
Hadoop itself doesn’t explicitly support this, but we can implicitly do this by configuring the first job to write to a specific directory and configuring the second job to read from that directory.
Now you can see how this becomes a dependency problem: if the first job in the chain fails, the second job cannot start since it depends on the first one. The tools that handle this is called a scheduler.
MapReduce schedulers are tools that help manage and schedule the execution of MapReduce jobs and other data processing tasks in a Hadoop cluster. These schedulers can automate job execution, manage dependencies, and monitor job progress. Some example schedulers include Apache Oozie, Azkaban, Nifi, Airflow etc.
Joins in MapReduce
In MapReduce, combining data from different sources based on a common key (e.g., user_id from a user activity log and a users database) is a frequent requirement. There are mainly two types of joins: reduce-side join and map-side join.
Reduce-Side Join
- Sort-Merge Join: This method involves sorting both datasets by the join key and then merging them during the reduce phase.
- How It Works: Mappers process input records and emit key-value pairs with the join key as the MapReduce key. In the reduce phase, the reducer performs the join operation on these collected values.
- Pros: Can handle large datasets that do not fit into memory.
- Cons: Inefficient due to extensive data shuffling and sorting.
- When to Use: Suitable for large datasets where in-memory storage is not feasible.
- Real-World Example: Useful for combining large-scale user activity data with user profiles for behavioral analysis.
Map-Side Join
- Hash Join: Effective when one of the datasets is small enough to be loaded into the memory of each mapper machine.
- How It Works: The smaller dataset is distributed to all mappers and loaded into memory. The mappers then process the larger dataset and perform joins with the data in memory.
- Pros: More efficient than reduce-side joins as it avoids shuffling and sorting.
- Cons: Feasible only if one dataset is small enough for in-memory storage.
- When to Use: Ideal for joining a large dataset with a small one.
- Real-World Example: Commonly used for joining large transaction logs with small lookup tables, such as product details.
Problems with MapReduce
- Mappers are often redundant. In many workflows, the only thing the mapper does is to read back the file written by the reducer and then pass it to another reducer. In these cases, the mapper is unnecessary. But the MapReduce programming model requires a mapper stage.
- Storing intermediate data on HDFS means it’s replicated and takes much space, which can be an overkill for temporary data.