






A user loads their profile page. The database query takes 50ms. Two seconds later, another user loads the same profile. The database runs the identical query again. Millions of users generate millions of duplicate queries. Each query reads from disk. Disk is slow. Memory is 50 times faster. Caching stores frequently accessed data in memory to eliminate redundant disk reads.
Why Memory Beats Disk
Understanding caching requires understanding storage hierarchy performance. Reading from main memory takes 100 nanoseconds. Reading from disk takes 8,000,000 nanoseconds for a seek plus 20,000,000 nanoseconds to read 1MB sequentially. Memory is more than 50 times faster than disk for typical database operations.
| Operation | Latency |
|---|---|
| execute typical instruction | 1 nanosec |
| fetch from L1 cache memory | 0.5 nanosec |
| fetch from L2 cache memory | 7 nanosec |
| fetch from main memory | 100 nanosec |
| send 2K bytes over 1Gbps network | 20,000 nanosec |
| read 1MB sequentially from memory | 250,000 nanosec |
| fetch from new disk location (seek) | 8,000,000 nanosec |
| read 1MB sequentially from disk | 20,000,000 nanosec |
| send packet US to Europe and back | 150,000,000 nanosec |
Source: Peter Norvig's latency numbers
This performance gap matters at scale. A database reading from disk handles thousands of queries per second. A cache reading from memory handles millions. For read-heavy workloads serving millions of users, this difference determines whether the system survives or collapses under load.
What Caching Is
Caching stores frequently accessed data in fast memory so subsequent requests avoid slow disk reads. When a user requests product information, the application first checks the cache. If the data exists in cache, return it from memory in microseconds. If not, query the database, store the result in cache, then return it. The next request for the same product reads from cache.
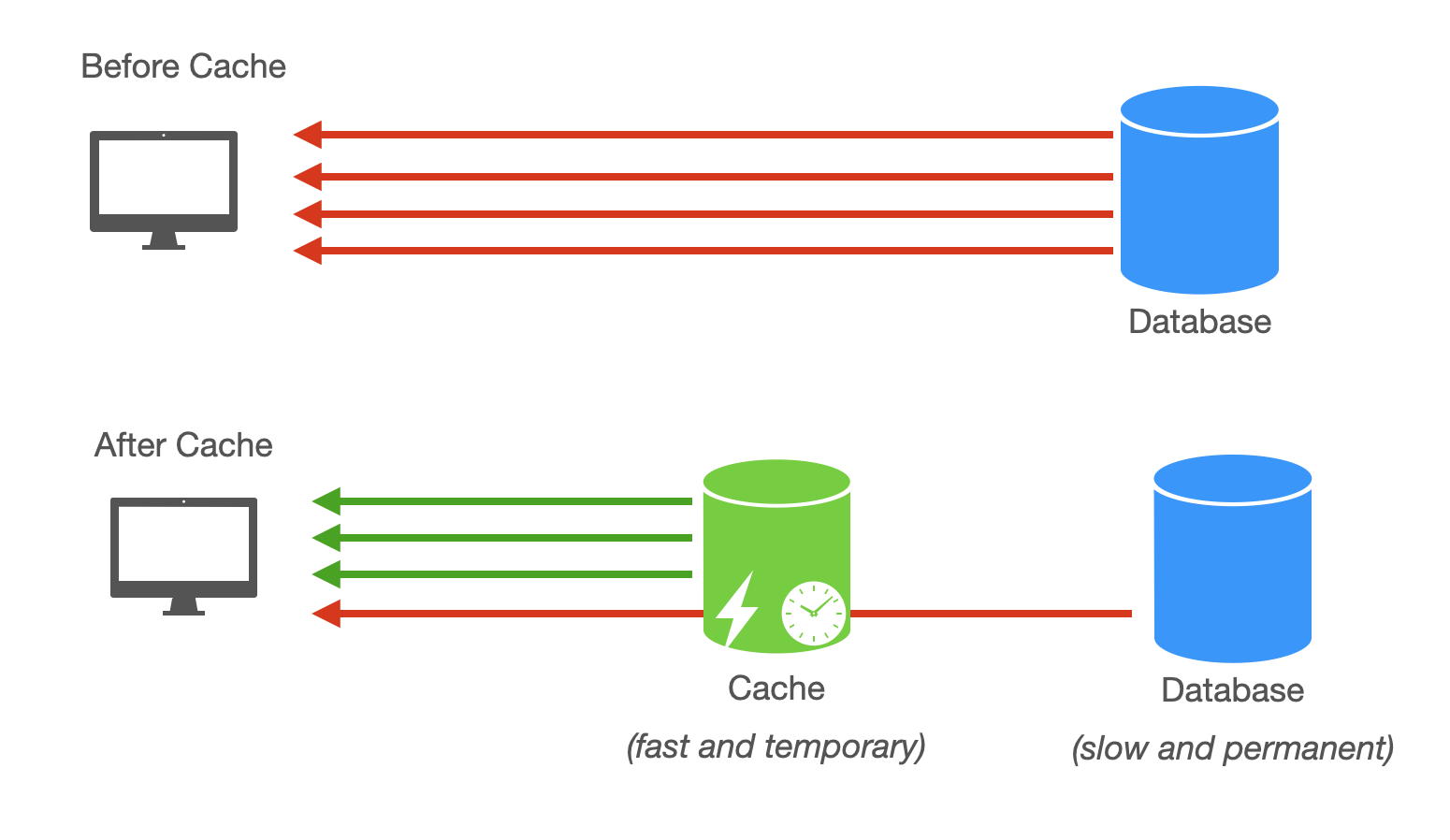

The cache sits between the application and the database. Popular data stays in cache. Unpopular data gets queried from the database each time. This works because access patterns follow power laws. A small fraction of data accounts for most requests. A video streaming service might have 100,000 videos, but the top 100 account for 80% of views. Caching those 100 videos eliminates 80% of database queries.
Caching improves query response time dramatically. Reading from memory delivers results in microseconds instead of milliseconds. Users see faster page loads and quicker interactions. The difference between 10ms and 100ms response time compounds across every query in a page load.
Caching relieves pressure on the database. Read-write separation distributes read load across replicas, but caching eliminates many reads entirely. Reducing read requests from web servers to the database means the database can support more web servers. A database handling 5,000 queries per second might struggle to scale further. A cache handling 95% of reads drops database load to 250 queries per second, allowing 10x more web servers.
Caching increases system capacity. Web servers retrieve data from fast cache memory instead of waiting on disk I/O. This allows each server to handle more concurrent requests. The same hardware serves more users when the bottleneck shifts from disk to memory.
Caching Beyond Memory
Caching applies at multiple levels. This article focuses on in-memory caching for web services, but the concept appears throughout systems.
Browser caching stores static assets like images, CSS, and JavaScript files on the user's device. The browser caches these files based on HTTP headers sent by the server. Subsequent page loads skip downloading unchanged files, improving load times without hitting the server.
Content Delivery Networks cache content geographically close to users. A CDN like Cloudflare or Akamai stores copies of static assets on servers worldwide. A user in Tokyo fetches images from a Tokyo data center instead of a server in Virginia. Latency drops from roughly 150ms to under 10ms. CDNs work best for static assets and large files like videos that change infrequently.
In-memory caching for web services uses systems like Redis or Memcached. This is the focus for system design interviews and the remainder of this article.
Redis and Memcached
Redis and Memcached are the two dominant in-memory caching technologies. Memcached pioneered web-scale caching. Facebook used Memcached to scale to millions of users in the 2010s. Redis emerged later with richer features and has become more popular for new systems.
The core difference is data structures. Memcached treats everything as binary blobs in key-value pairs. Redis supports strings, lists, sets, sorted sets, hashes, and bitmaps. This enables atomic operations like increments and list manipulations.
| Feature | Redis | Memcached |
|---|---|---|
| Data Structures | Strings, lists, sets, sorted sets, hashes, bitmaps | Key-value pairs (strings or binary data) |
| Persistence | Optional (saves to disk, recovers after restart) | No (in-memory only) |
| Atomic Operations | Yes (increments, list manipulations) | No |
| Pub/Sub | Yes (publish/subscribe messaging) | No |
| High Availability | Yes (Redis Sentinel and Redis Cluster) | No (requires third-party solutions) |
| Cache Eviction Policy | Configurable (LRU, LFU, volatile, all keys) | Least Recently Used (LRU) |
| Use Cases | Advanced data structures, real-time apps | Simple caching, session storage |
| Companies Using | Twitter, GitHub, Stack Overflow | Facebook, YouTube, Reddit |
Redis adds complexity with more features. Memcached stays simple and straightforward. For basic caching needs, Memcached works well. For applications needing data structures, pub/sub, or persistence, Redis provides those capabilities.
Caching Challenges
Phil Karlton famously said there are only two hard things in computer science: cache invalidation and naming things. Cache consistency is the core challenge. When data updates in the database, the cached copy becomes stale. Multiple users accessing the same data might see different versions. One user updates a product price. Another user still sees the old price from cache. Without proper invalidation, stale data persists indefinitely.
Expiry and eviction require careful tuning. Caches operate in limited memory. You must decide when items expire to prevent serving stale data. You must choose an eviction strategy for when cache fills up. Should the system remove the least recently used items? The least frequently used? Items closest to expiry? Each strategy has trade-offs.
Fault tolerance matters because cache failures lose data. Caches live in memory. A server crash wipes the cache. The system must fall back to the database when cache fails. This increases latency and database load until the cache rebuilds. The system must handle this gracefully without cascading failures.
Caching Patterns Overview
The following articles explore specific patterns for addressing these challenges. Reading patterns determine how data enters the cache. Cache-aside loads data on demand when a cache miss occurs. Read-through makes the cache responsible for fetching from the database.
Writing patterns determine when updates reach the cache. Write-through updates cache and database simultaneously. Write-back writes to cache first and persists to database later. Write-around bypasses cache and writes directly to the database.
Eviction patterns decide what gets removed when cache fills. Least Recently Used discards items not accessed recently. Time-to-live removes items after a fixed duration. Choosing the right pattern depends on your access patterns and consistency requirements.
These patterns are explored in detail below, starting with cache-aside, the most common reading pattern. Understanding when to use each pattern and their trade-offs is essential for system design interviews.