






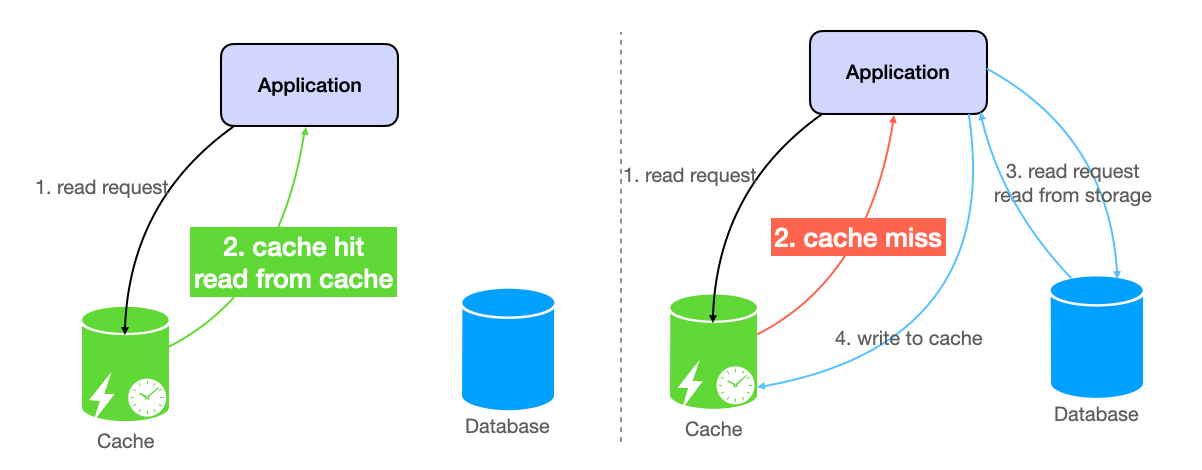
A user profile request hits your server. The application checks Redis for cached data. The key does not exist. The application queries PostgreSQL, stores the result in Redis, and returns the profile. Two seconds later, another user requests the same profile. This time Redis contains the data. The application returns it from cache without touching the database. This is cache-aside, also called lazy loading.
The cache sits on the side of the primary data store. It does not actively manage data. The application is responsible for loading data into cache when needed. The cache and database are separate systems that do not interact with each other.
How it works
In a cache-aside pattern, the application is responsible for loading data into the cache when needed. Cache and database are both separate systems and do not interact with each other.
Read operation
- Attempts to read from cache: When the application needs data, it first checks the cache to see if it's already available.
- If not found, cache miss: If the data is not found in the cache, this is called a cache miss.
- Read from data source and save in memory: When a cache miss occurs, the application fetches the data from the main data source (e.g., a database), saves it in the cache, and returns it to the user.

Write operation
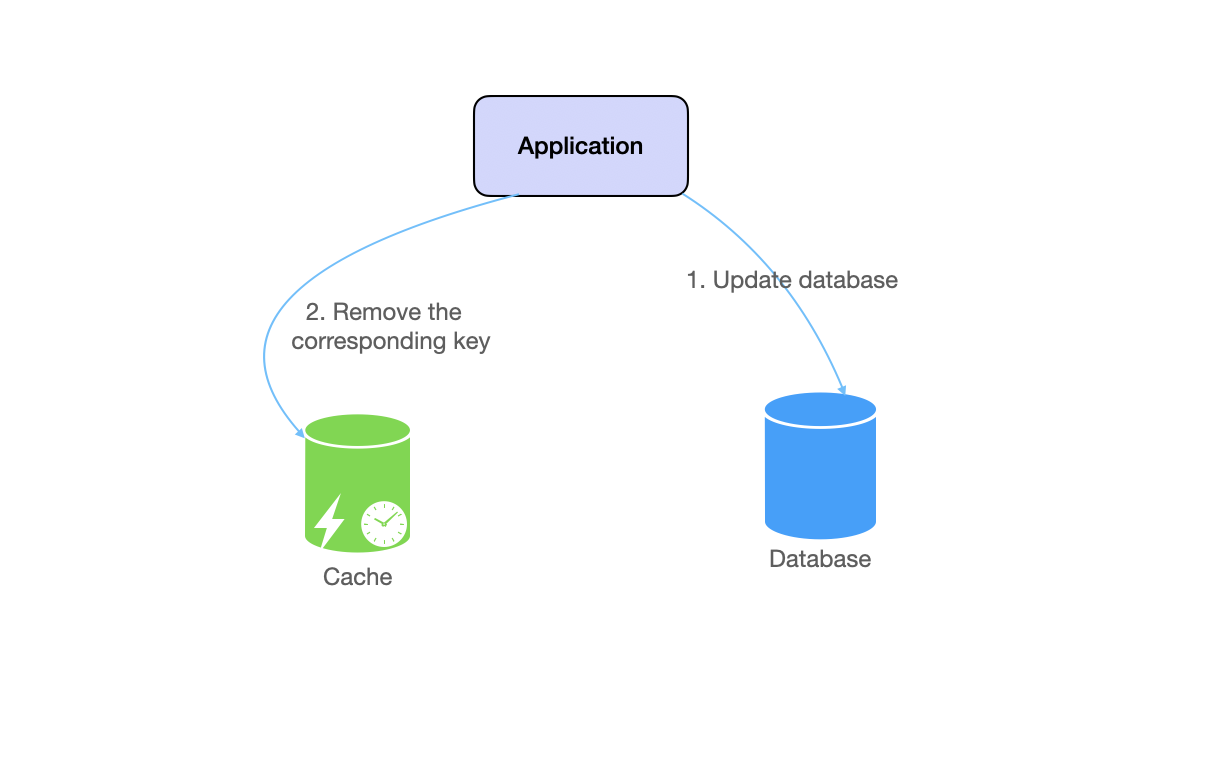
- Update the database.
- Remove the corresponding key from the cache, aka invalidate the cache.
Note that we don't need to update the cache with the new data, because the next read operation will fetch the updated data from the database. This is why it's called "lazy loading" and "cache-aside".
Implementation Example
Let's create a Flask server that connects to the PostgreSQL database and uses Redis for caching with lazy loading pattern:
Imagine we have users and comments data stored in PostgreSQL like this:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com');
CREATE TABLE comments (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
);
INSERT INTO comments (content, user_id) VALUES
('Great post!', 1),
('Interesting read.', 1),
('Thanks for sharing!', 2),
('I learned something new today.', 2),
('Very insightful!', 3);And our app uses this query to get user details
SELECT users.id, users.name, users.email, comments.id, comments.content
FROM users
JOIN comments ON users.id = comments.user_id
WHERE users.name = %s AND users.email = %s;Now let’s use the query as a cache key and implement lazy loading.
from flask import Flask, jsonify, request
import redis
import psycopg2
import json
app = Flask(__name__)
# Connect to Redis
cache = redis.Redis(host='localhost', port=6379, db=0)
# Database configuration
db_config = {
"dbname": "your_database_name",
"user": "your_user",
"password": "your_password",
"host": "your_host",
"port": "your_port"
}
def fetch_data_from_database(name, email):
conn = psycopg2.connect(**db_config)
cursor = conn.cursor()
query = '''
SELECT users.id, users.name, users.email, comments.id, comments.content
FROM users
JOIN comments ON users.id = comments.user_id
WHERE users.name = %s AND users.email = %s;
'''
cursor.execute(query, (name, email))
data = cursor.fetchall()
conn.close()
return data
def get_data(name, email):
# Generate a cache key from the query parameters
cache_key = f"comments:name={name}:email={email}"
data = cache.get(cache_key)
# Cache miss
if data is None:
print(f"Fetching data for name={name} and email={email} from database...")
data = fetch_data_from_database(name, email)
if data:
cache.set(cache_key, json.dumps(data), ex=600) # Set a TTL of 600 seconds
else:
print(f"No comments found for name={name} and email={email}")
return None
# Cache hit
else:
print(f"Fetching data for name={name} and email={email} from cache...")
data = json.loads(data.decode('utf-8'))
return data
@app.route('/comments')
def get_comments():
name = request.args.get('name', '')
email = request.args.get('email', '')
data = get_data(name, email)
if data:
return jsonify([
{
"user_id": row[0],
"user_name": row[1],
"user_email": row[2],
"comment_id": row[3],
"comment_content": row[4]
}
for row in data
])
else:
return jsonify({"error": f"No comments found for name={name} and email={email}"}), 404
if __name__ == '__main__':
app.run(debug=True)The implementation demonstrates several caching concepts. The cache key is a unique identifier for stored data. We generate cache keys from query parameters like comments:name={name}:email={email} to ensure each unique combination has its own cache entry. This differentiates between queries and caches their results separately.
Grasping the building blocks ("the lego pieces")
This part of the guide will focus on the various components that are often used to construct a system (the building blocks), and the design templates that provide a framework for structuring these blocks.
Core Building blocks
At the bare minimum you should know the core building blocks of system design
- Scaling stateless services with load balancing
- Scaling database reads with replication and caching
- Scaling database writes with partition (aka sharding)
- Scaling data flow with message queues
System Design Template
With these building blocks, you will be able to apply our template to solve many system design problems. We will dive into the details in the Design Template section. Here’s a sneak peak:
Additional Building Blocks
Additionally, you will want to understand these concepts
- Processing large amount of data (aka “big data”) with batch and stream processing
- Particularly useful for solving data-intensive problems such as designing an analytics app
- Achieving consistency across services using distribution transaction or event sourcing
- Particularly useful for solving problems that require strict transactions such as designing financial apps
- Full text search: full-text index
- Storing data for the long term: data warehousing
On top of these, there are ad hoc knowledge you would want to know tailored to certain problems. For example, geohashing for designing location-based services like Yelp or Uber, operational transform to solve problems like designing Google Doc. You can learn these these on a case-by-case basis. System design interviews are supposed to test your general design skills and not specific knowledge.
Working through problems and building solutions using the building blocks
Finally, we have a series of practical problems for you to work through. You can find the problem in /problems. This hands-on practice will not only help you apply the principles learned but will also enhance your understanding of how to use the building blocks to construct effective solutions. The list of questions grow. We are actively adding more questions to the list.

