






Availability is one of the most fundamental requirements for system design. You've probably heard the term “high availability” a lot in tech talks. People like to boast about their service being “highly available”. But what does it mean exactly?
What is Availability?
High availability refers to the ability of a system to operate continuously, without failure, for a significantly long period. It's a crucial element of system design that ensures systems can provide services to users as intended without unplanned downtimes.
Let's simplify with a pizza example. If it's open when you expect it to be and serves you pizza whenever you want, then it has high availability. In computer systems, this means the system is working and can be used whenever it's needed.
Measuring Availability
Availability is often defined as the percentage of time that a system is operational and able to provide service as expected.
If your favorite pizza place is open 24/7 then it's 100% availability. 100% availability is virtually impossible in a computing environment.
Here's the formula to calculate availability:
Availability (%) = (Total operational time / Total time) x 100Here are the steps on how to calculate it:
-
Identify the Total Time: This is typically the total amount of time for which you're evaluating the system's availability. It could be a day, week, month, year, etc.
-
Identify the Downtime: This is the total amount of time during the period under evaluation that the system was not operational. This could be due to system crashes, maintenance, network issues, etc.
-
Calculate the Operational Time: This is done by subtracting the downtime from the total time.
Total Operational Time = Total Time - Downtime
-
Calculate Availability: Divide the operational time by the total time, then multiply the result by 100 to get a percentage.
Availability (%) = (Total Operational Time / Total Time) x 100
For example, if you are evaluating system availability over the course of a year (which has 3652460 = 525,600 minutes), and the system was down for a total of 500 minutes during that time:
Total Operational Time = 525,600 minutes - 500 minutes = 525,100 minutes
Availability (%) = (525,100 minutes / 525,600 minutes) x 100 ≈ 99.905%This means the system was available approximately 99.905% of the time.
What is “High” Availability?
Now, how good is 99.905% availability? Is it considered “highly” available?
High availability is often talked about in terms of "nines". If something has "five nines" (99.999%) availability, it's like saying your pizza place is open 99.999% of the time. This means it's only closed about 5 minutes a year! That is a pretty highly available system. Here’s a table from Wikipedia showing availability percentage to the downtime to give you a feel of how the number of 9s would require.
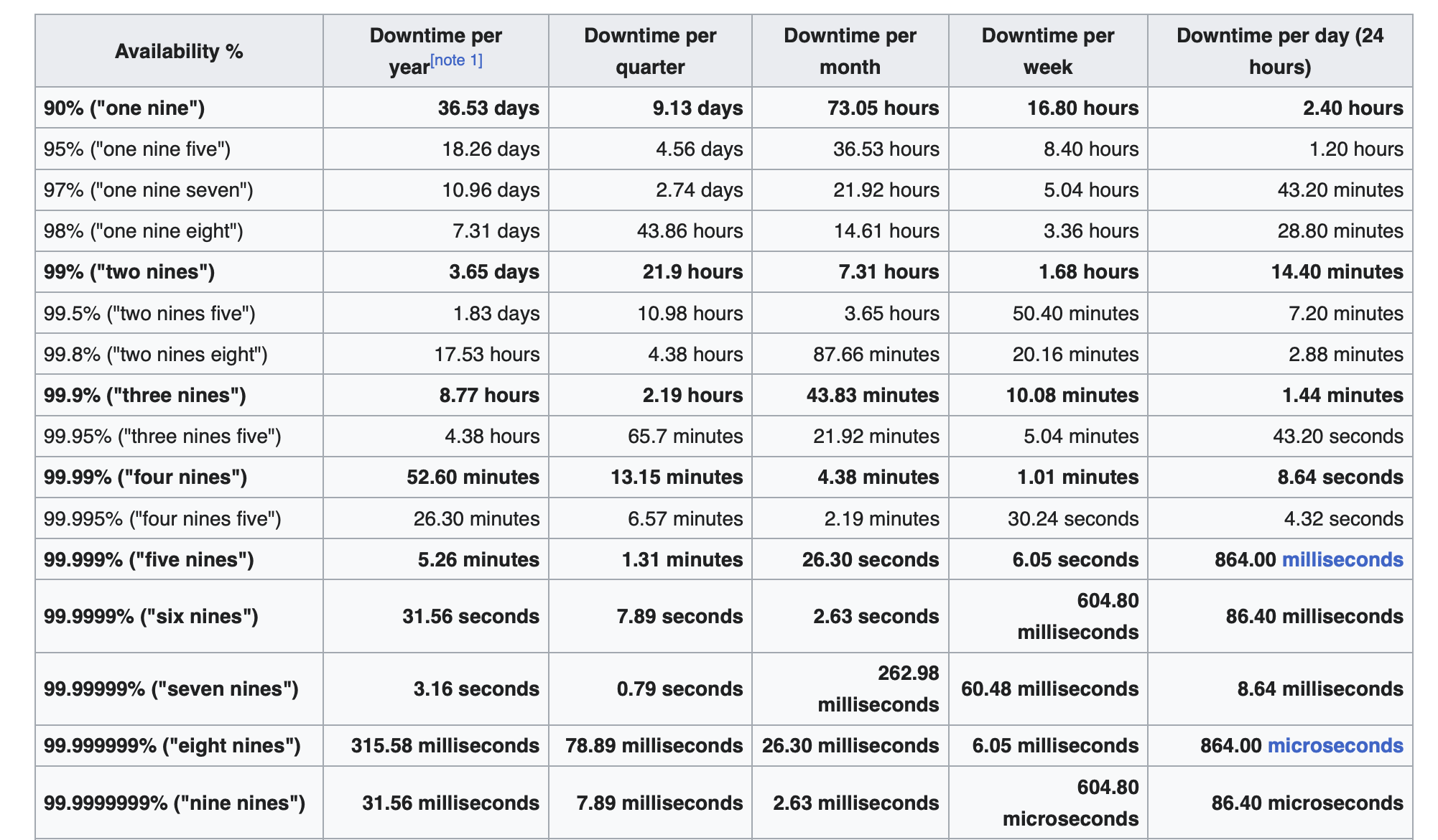

But, how many nines are good enough for my system, or is it even necessary? To answer that we first have to discuss Service Level Agreement (SLA).
Service Level Agreement (SLA)
A Service Level Agreement (SLA) is a formal, written agreement between a service provider and a customer that sets expectations regarding the level of service the provider will deliver. This often includes specific metrics and targets the service provider agrees to meet, such as system uptime, response time, and resolution time.
For example, an SLA might stipulate that a system will have an uptime of 99.9% (three nines), and any breach of this may result in penalties, often in the form of service credits to the customer.
SLAs are important because they clearly establish expectations for both the service provider and the customer, offer a standard to measure service performance, and set out remedies or penalties if the service levels aren't met.
For example, here's a screenshot from Google Cloud's compute engine service's SLA:

It specifies the availability uptime in different scenarios and what Google offers to compensate the customers if it fails to achieve them.
Cloud providers typically publish SLAs for their services:
Note that availability is not the only property that can be specified in an SLA. For example, durability might also be specified as part of the provider's commitments. For example, Amazon S3, the cloud storage service from Amazon Web Services (AWS), is designed for roughly 11 nines of annual durability (99.999999999%). This design target implies that if you store 10,000,000 objects in Amazon S3, you would expect to lose a single object about once every 10,000 years. We will discuss more about durability in the coming articles.