






Introduction
Before diving into the reusable building blocks of distributed system design, readers should have a fair understanding of what the common challenges are. They arise from serving the very large scale of user-base by adding more machines. Without a huge number of users, all system design problems scale back to coding problems. Like the solutions assembled from reusable building blocks, the challenges have several repeatable patterns. I hope to present the four challenges in a way that anyone who clears coding interviews can easily understand. Hopefully, the later jargon-rich content will make more sense after we understand what problems they are solving.
Challenge 1: Too Many Concurrent Users
While a large user-base introduces many problems, the most common and intuitive one is that a single machine/database has a RPS/QPS limit. In all single-server demo apps you would see in a web dev tutorial, the server’s performance will degenerate fast once the limit is exceeded.
The solution is also intuitive: repetition. We just repeat the same assets of our app and assign the users randomly to each replication. When the replicated assets are server logic, it's called load balancing. When the replicated assets are data, it's usually called database replicas. More in load balancer and database replication.
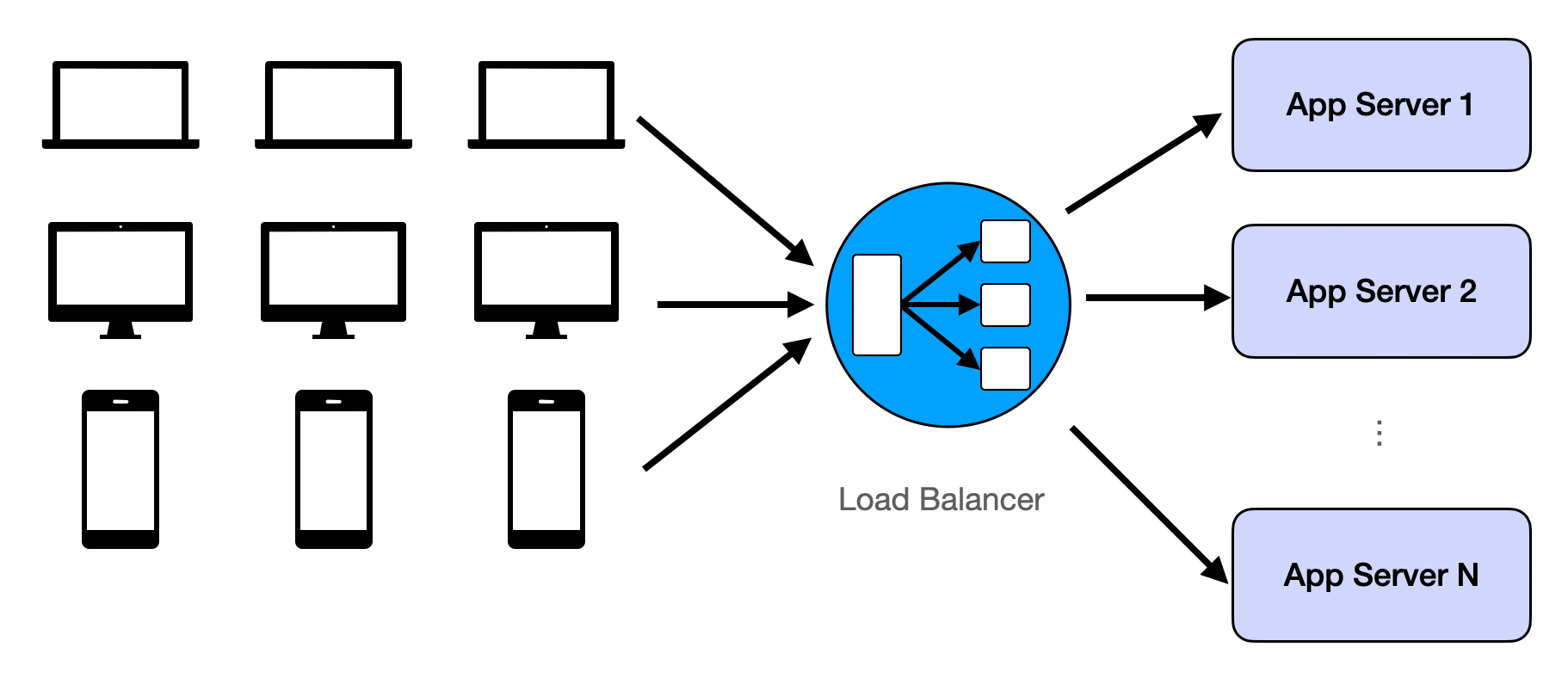

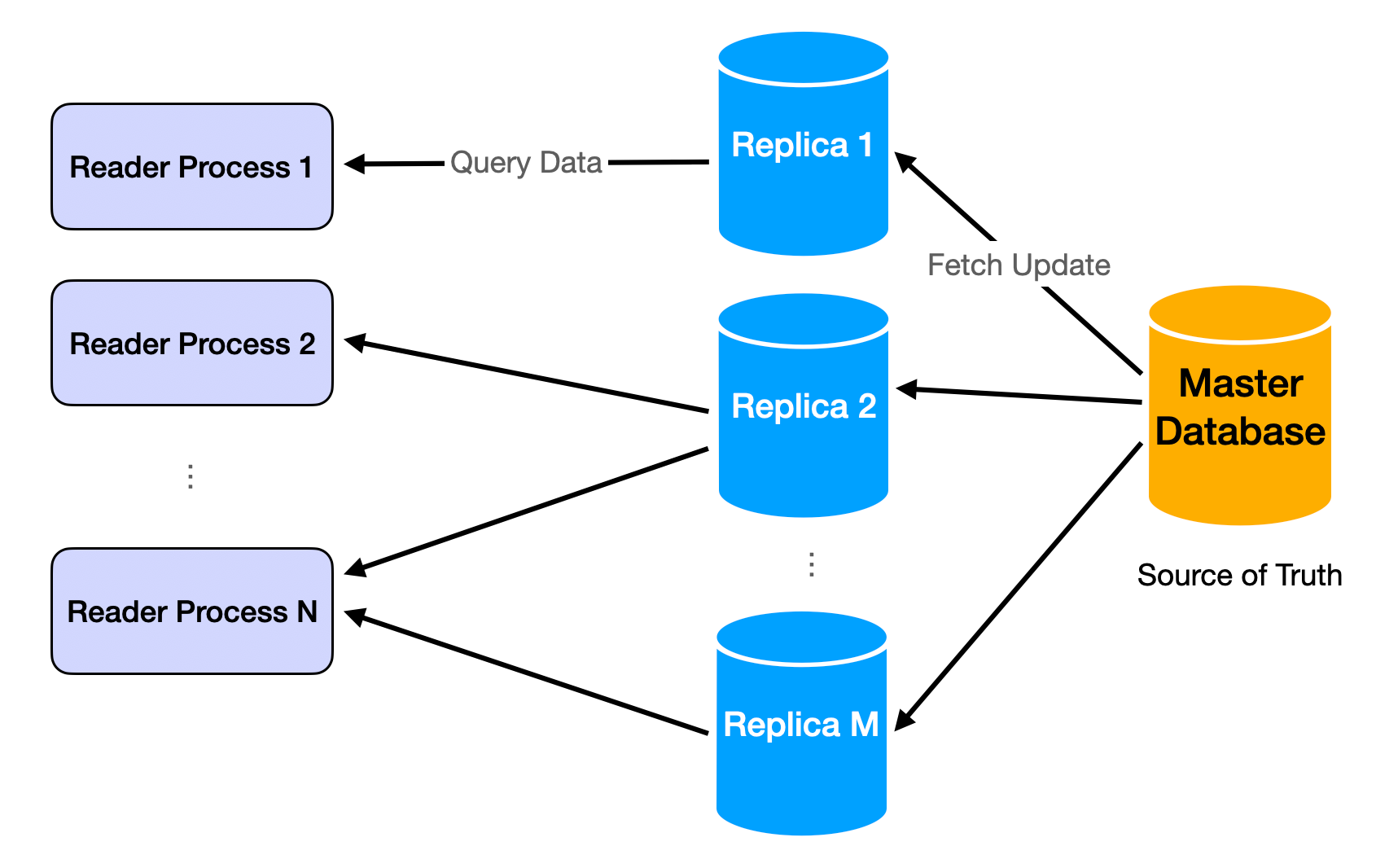
Challenge 2: Too Much Data to Move Around
The twin challenge of too many users is the issue of too much data. The data becomes 'big' when it's no longer possible to hold everything on one machine. Some common examples: Google index, all the tweets posted on Twitter, all movies on Netflix.
Grasping the building blocks ("the lego pieces")
This part of the guide will focus on the various components that are often used to construct a system (the building blocks), and the design templates that provide a framework for structuring these blocks.
Core Building blocks
At the bare minimum you should know the core building blocks of system design
- Scaling stateless services with load balancing
- Scaling database reads with replication and caching
- Scaling database writes with partition (aka sharding)
- Scaling data flow with message queues
System Design Template
With these building blocks, you will be able to apply our template to solve many system design problems. We will dive into the details in the Design Template section. Here’s a sneak peak:
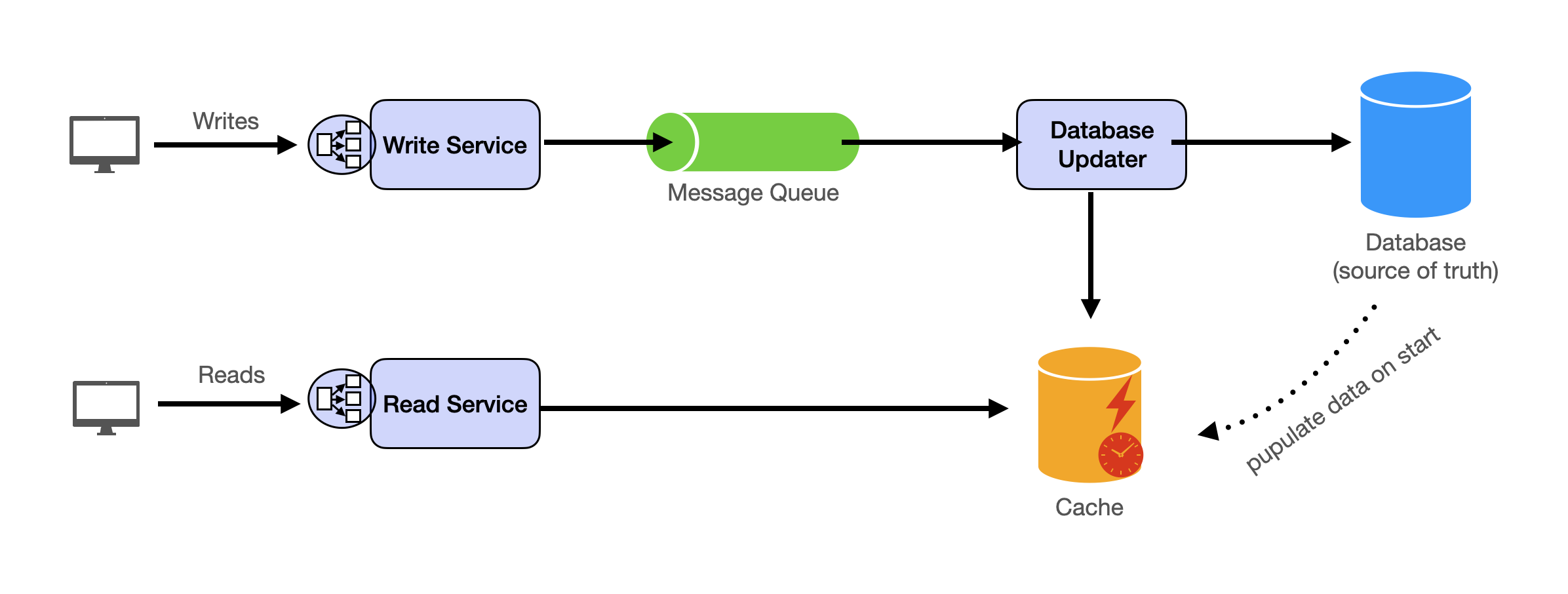
Additional Building Blocks
Additionally, you will want to understand these concepts
- Processing large amount of data (aka “big data”) with batch and stream processing
- Particularly useful for solving data-intensive problems such as designing an analytics app
- Achieving consistency across services using distribution transaction or event sourcing
- Particularly useful for solving problems that require strict transactions such as designing financial apps
- Full text search: full-text index
- Storing data for the long term: data warehousing
On top of these, there are ad hoc knowledge you would want to know tailored to certain problems. For example, geohashing for designing location-based services like Yelp or Uber, operational transform to solve problems like designing Google Doc. You can learn these these on a case-by-case basis. System design interviews are supposed to test your general design skills and not specific knowledge.
Working through problems and building solutions using the building blocks
Finally, we have a series of practical problems for you to work through. You can find the problem in /problems. This hands-on practice will not only help you apply the principles learned but will also enhance your understanding of how to use the building blocks to construct effective solutions. The list of questions grow. We are actively adding more questions to the list.