Problem statement
Design a file-sync service like Dropbox: a folder of files lives on many devices, and when a user edits a file on one device, the change appears on every other device within seconds.
In scope: syncing changes across devices, uploading and downloading files efficiently, transferring only what changed, and resolving conflicting edits. Real-time character-by-character collaborative editing, full-text search over file contents, and sharing permissions are out of scope.
Clarifying questions
Each answer fixes an assumption the design leans on.
- Sync across devices, or just backup? The interesting problem is multi-device sync — many devices holding the same folder, converging within seconds of each edit.
- Whole files, or real-time collaborative editing? Whole-file sync: a save produces a new file version. Real-time, keystroke-level editing is a different problem, covered in Google Docs.
- Sharing and permissions? Assume a namespace (a personal or shared folder) as the unit of sync; access control is deferred.
- Full-text search over file contents? A separate indexing problem, deferred.
- How fast must changes propagate? Seconds, not minutes — polling fast enough to meet that is expensive at scale, which pushes the design toward push notification.
What makes this problem distinctive
A user edits one paragraph of a large document and hits save; two seconds later, another device shows the update. What actually crossed the network? If the answer is "the whole file got re-uploaded," or "the other device keeps asking 'changed yet?'," that's only the easy half of the problem. The bytes are large but static once written — storage itself is the secondary concern.
The hard half is the sync engine: detecting exactly what changed, moving only that delta, and keeping every device converged on the same current version even when edits happen concurrently and offline. This is a sync problem before it is a storage problem, and the two halves have almost opposite characters — the bytes are huge and rarely change once written, while the metadata describing what changed is small, mutable, and sits on every single save.
Key idea. This is a sync problem, not a storage problem — the bytes are the large, easy half; detecting the delta, propagating it fast, and reconciling concurrent edits is the hard half.
Key concepts
This section covers the concepts needed to solve this problem — prerequisites for the design work that follows.
Content-addressed blocks
A file is split into blocks, each named by a hash of its own bytes rather than its position in the file. Two blocks with identical content always get the same hash, anywhere, which makes an upload check trivial: send the hashes you have, and the server tells you which ones it's missing. This is the mechanism behind both delta sync (only upload blocks the server doesn't already have) and deduplication (two users' identical blocks are stored once), the same content-addressing idea covered in object storage. Cross-user dedup assumes blocks are not encrypted with per-user keys — encrypted that way, identical content produces different stored bytes, and the match disappears.
The metadata service as authority
While block bytes are immutable and can live anywhere, something has to own the single question "what is the current version of this file?" — and answer it the same way for every device, every time. A metadata service is that authority: it tracks each file's version history and commits a new version atomically; because every device asks this one authority rather than a stale copy, "current" never means two different things to two devices at once.
Versions, not overwrites
Each save produces a new version — an ordered list of block hashes plus a pointer to the version it was edited from (its parent_version) — rather than mutating a file in place. Keeping that lineage is what makes it possible to detect, later, whether two devices edited from the same starting point or from two different ones.
Push notification with a poll fallback
A device that just committed a change needs every other device watching that folder to find out within seconds, not by asking on a timer. A lightweight, payload-free notification — "namespace N changed" — pushed over a persistent connection is enough to trigger a device to go pull the actual delta. Because the notification carries no data and the metadata service remains the authority regardless, a dropped notification is not a correctness problem: a periodic background poll catches anything a missed push didn't, so a failure makes sync slower, never wrong.
Key idea. Content-addressed blocks make delta sync and dedup the same mechanism; the metadata service is the single authority on "current version," never the block store; versions form a lineage a conflict check can reason about; and push notification is a fast, best-effort trigger sitting on top of a poll fallback that's always correct.
Grasping the building blocks ("the lego pieces")
This part of the guide will focus on the various components that are often used to construct a system (the building blocks), and the design templates that provide a framework for structuring these blocks.
Core Building blocks
At the bare minimum you should know the core building blocks of system design
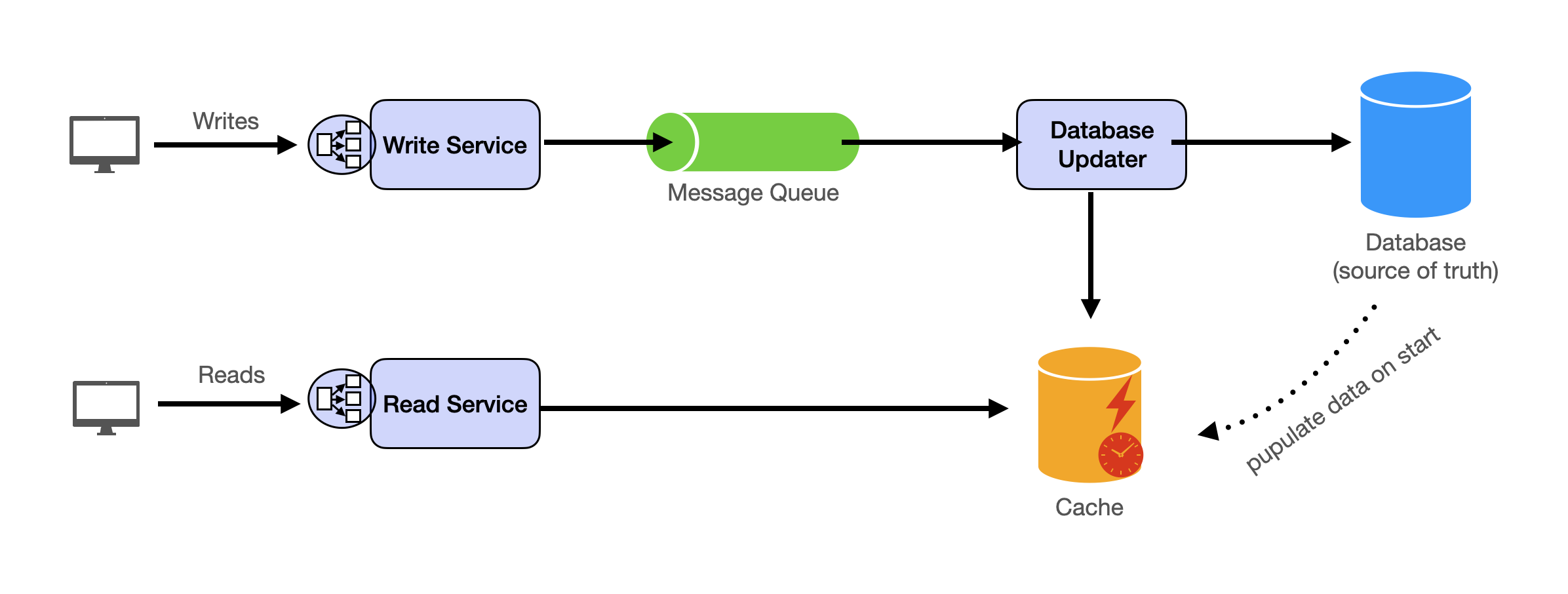
- Scaling stateless services with load balancing
- Scaling database reads with replication and caching
- Scaling database writes with partition (aka sharding)
- Scaling data flow with message queues
System Design Template
With these building blocks, you will be able to apply our template to solve many system design problems. We will dive into the details in the Design Template section. Here’s a sneak peak:

Additional Building Blocks
Additionally, you will want to understand these concepts
- Processing large amount of data (aka “big data”) with batch and stream processing
- Particularly useful for solving data-intensive problems such as designing an analytics app
- Achieving consistency across services using distribution transaction or event sourcing
- Particularly useful for solving problems that require strict transactions such as designing financial apps
- Full text search: full-text index
- Storing data for the long term: data warehousing
On top of these, there are ad hoc knowledge you would want to know tailored to certain problems. For example, geohashing for designing location-based services like Yelp or Uber, operational transform to solve problems like designing Google Doc. You can learn these these on a case-by-case basis. System design interviews are supposed to test your general design skills and not specific knowledge.
Working through problems and building solutions using the building blocks
Finally, we have a series of practical problems for you to work through. You can find the problem in /problems. This hands-on practice will not only help you apply the principles learned but will also enhance your understanding of how to use the building blocks to construct effective solutions. The list of questions grow. We are actively adding more questions to the list.