Design Webhook
Introduction
Webhooks allow systems to send real-time notifications triggered by specific events. Unlike traditional APIs, which rely on polling, webhooks push data immediately when an event occurs, making them highly efficient and real-time.
Background
Webhooks are a common way to receive real-time notifications from external systems. They are widely used in modern web applications, including payment processing, social media updates, and event ticketing systems. Unlike traditional APIs, which rely on polling, webhooks push data immediately when an event occurs, making them highly efficient and real-time.
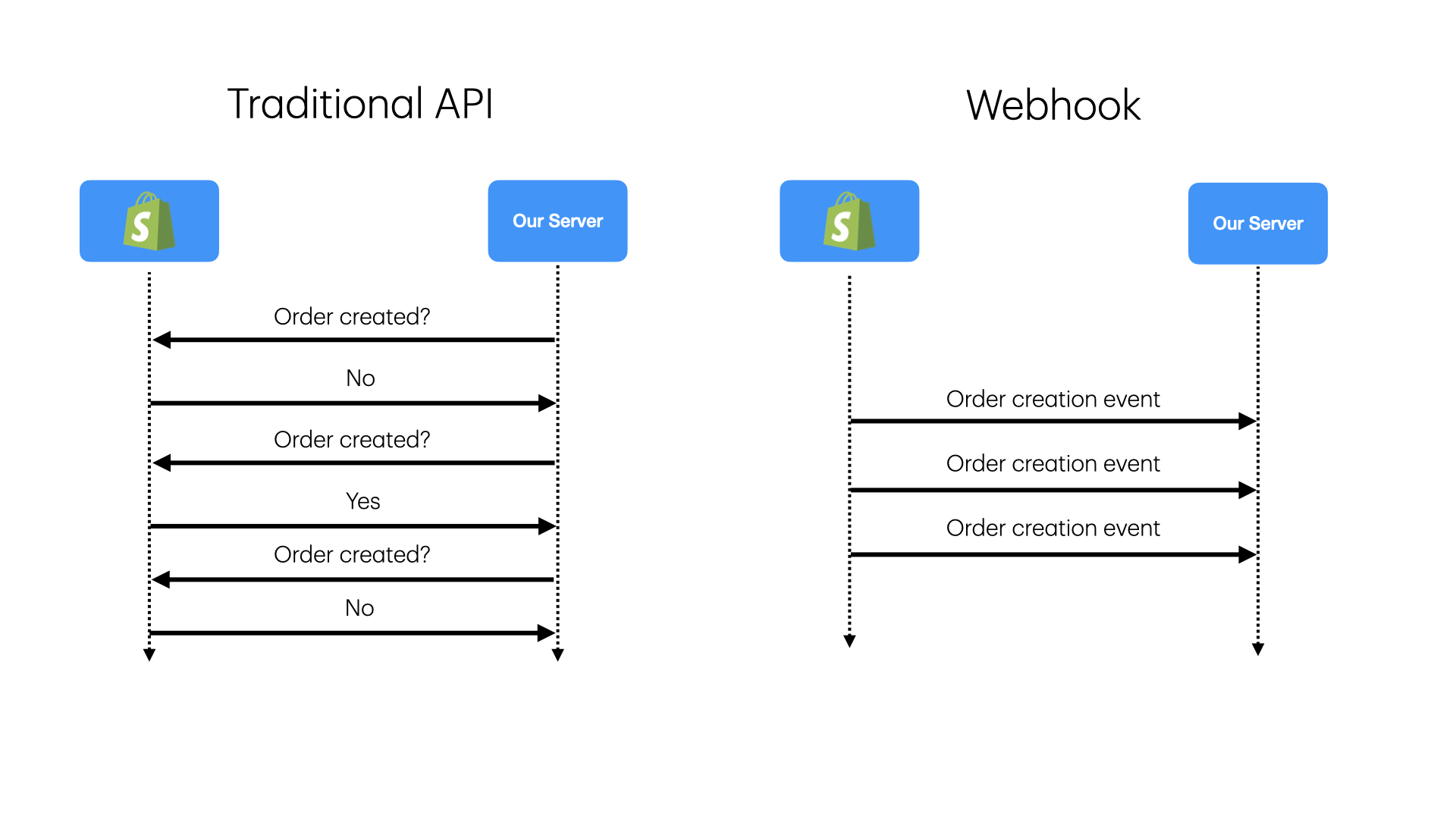

Here are some real-world examples:
Functional Requirements
-
Accept API calls to receive event notifications (e.g., payment processed or order shipped), execute corresponding operations, and persist original event data and operation results for tracking, auditing, and debugging.
-
The service must ensure events are processed even if system components fail, maintaining reliability for critical data.
Scale Requirements
- Event Volume: The system should handle 1 million events per day.
- Traffic Spikes: During peak hours, incoming requests may increase by 5 times.
- Latency Requirement: End-to-end latency (from event arrival to processing completion) should be under 200 milliseconds.
- Data Retention: The system should store all events for 30 days. Assume each event is 5KB.
Non-Functional Requirements
- High availability: The system should be highly available and resilient to failures.
- Low latency: As mentioned in the scale requirement, end-to-end latency should be under 200 milliseconds.
- At-least-once processing: Each event should be processed at least once if the system accepts it.
API Endpoints
/webhookReceive webhooks from external systems, returns 200 OK if the event is accepted.
High Level Design
1. Accept API Calls to Receive Event Notifications
Accept API calls to receive event notifications (e.g., payment processed or order shipped), execute corresponding operations, and persist original event data and operation results for tracking, auditing, and debugging.
Let’s start with a basic design. When an external system sends an event via an HTTP request, the webhook service needs a request handler to receive and process the event. This data is then immediately saved into a database.
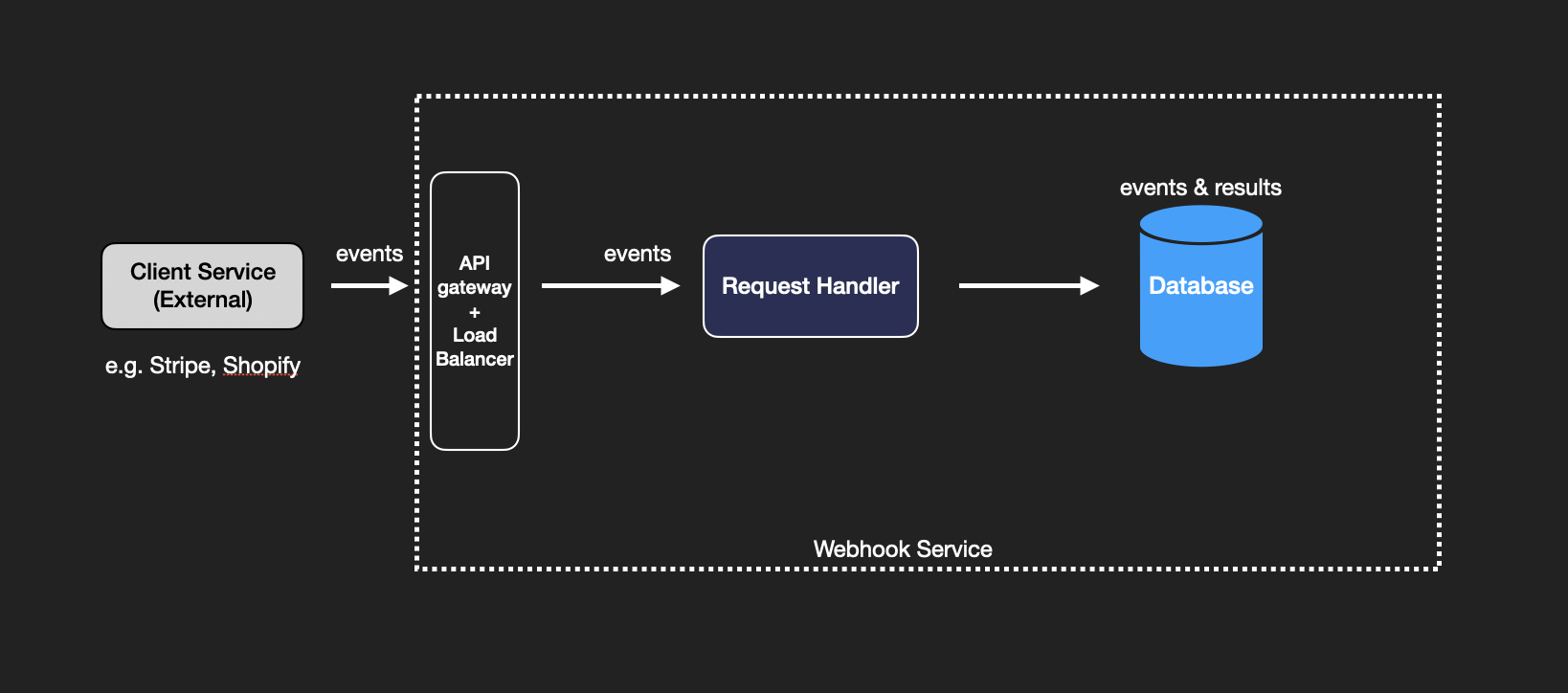
While straightforward, this design has a flaw. The request handlers handle the HTTP requests as well as the business logic of processing and persisting the events. If the request handler fails after processing the event but before saving it, the event could be lost.
2. High Availability and Resilience
The service must ensure events are processed even if system components fail, maintaining reliability for critical data.
Buffering with Message Queue
To address issues from the basic design, we can introduce a message queue between the request handler and the database.
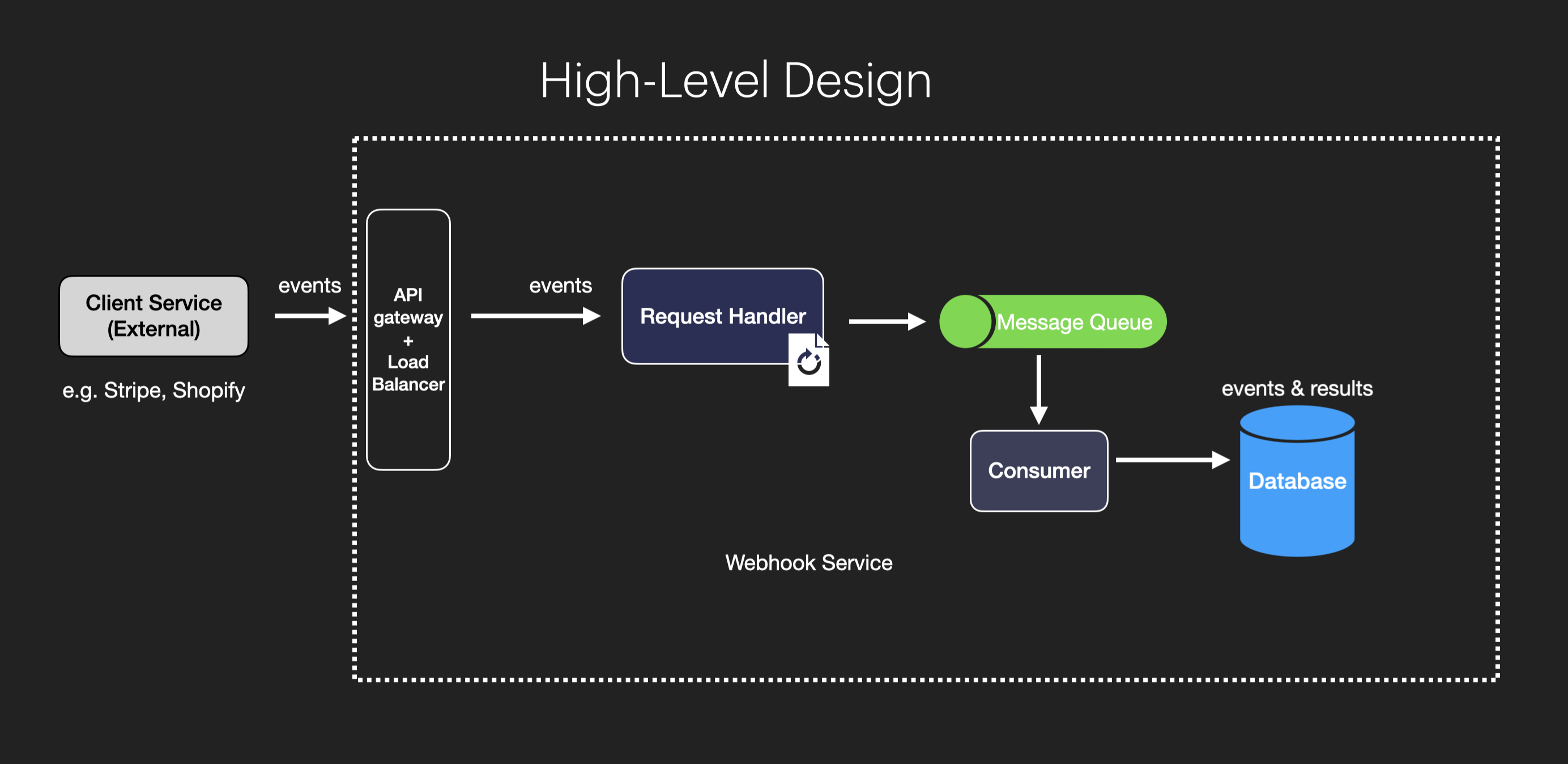
We reduce the responsibility of the request handler to handle initial HTTP requests and let the message queue consumer do the heavy lifting of processing the actual event. The message queue temporarily holds events, ensuring that no data is lost, even if the system experiences issues. The request handler now focuses on handling HTTP requests and enqueuing messages, while separate consumers process these events from the queue and save them to the database.
This design offers several benefits, including failure recovery, load buffering, and scalability.
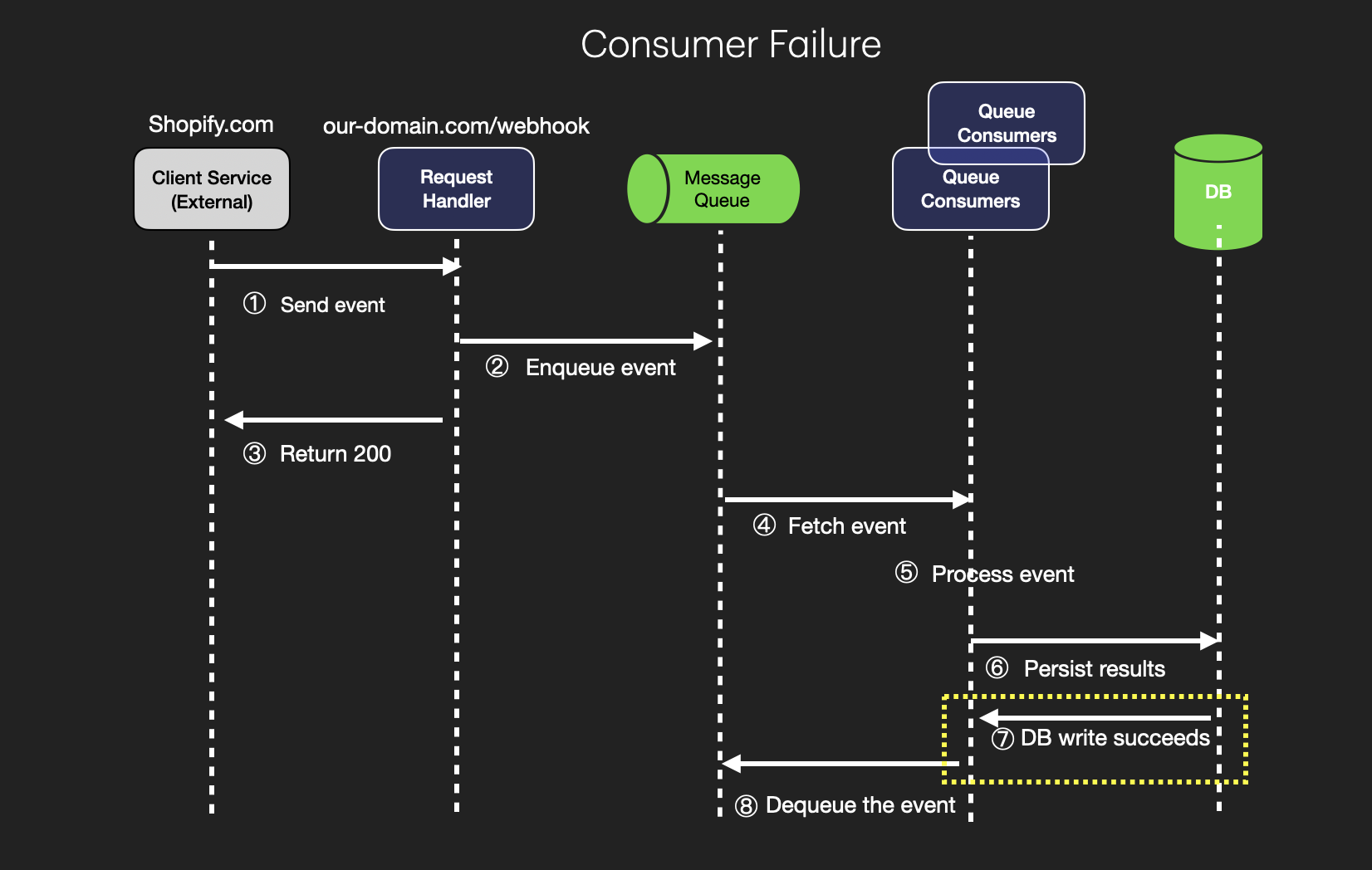
Here's the sequence diagram for the design:
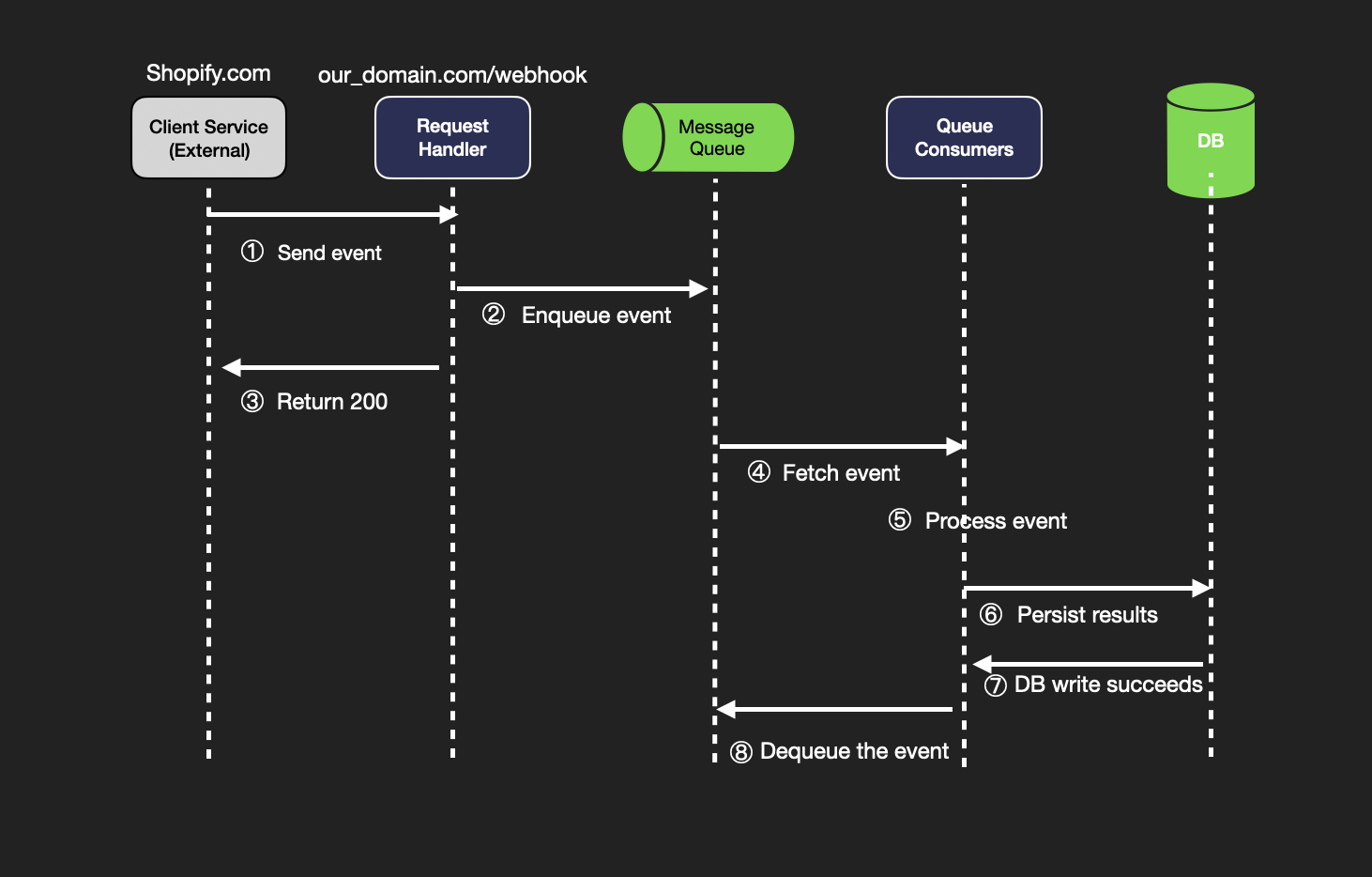
Here's what happens at each step:
-
Send Event: The external client service (e.g., Shopify.com) triggers an event and sends it to the webhook service's endpoint (our_domain.com/webhook). This event could represent a specific action, like a payment confirmation or order update.
-
Enqueue Event: The Request Handler in the webhook service receives the event and enqueues it into a Message Queue. This action stores the event temporarily, allowing the system to process events asynchronously, improving reliability and scalability.
-
Return 200: After enqueuing the event successfully, the Request Handler immediately returns a 200 HTTP status code to the client, confirming that the webhook event has been received. This acknowledgment allows the client to know the event was accepted, even if processing hasn't yet occurred.
-
Fetch Event: A Queue Consumer fetches the event from the Message Queue. This component is responsible for processing events one by one (or in batches, depending on design) as they become available in the queue.
-
Process Event: The Queue Consumer processes the event, which involves performing the necessary operations related to the event. For example, if it’s a payment confirmation, it may update the payment status in the system.
-
Persist Results: After processing, the Queue Consumer persists the results of the operation to a database. This could involve storing details like the original event, the outcome of the processing, and any relevant status updates.
-
DB Write Succeeds: Once the results are successfully saved in the database, the system receives confirmation of a successful write operation. This ensures that the event processing has been completed and recorded for future reference, such as for audits or debugging.
-
Dequeue the Event: After the event has been successfully processed and stored, it is dequeued from the Message Queue. This marks the event as fully handled, removing it from the queue and freeing up space for new incoming events.
Handling Failure in Each Component
In a webhook processing service, maintaining reliability and resilience in the face of potential failures is crucial for ensuring that events are not lost and that the system can recover smoothly. Let’s break down how each component can be designed to handle failures effectively.
1. Request Handler Failures
The request handler is responsible for receiving incoming events from external services and enqueuing them for further processing. Failures at this stage can lead to lost events if not managed carefully. Here are strategies for handling these failures:
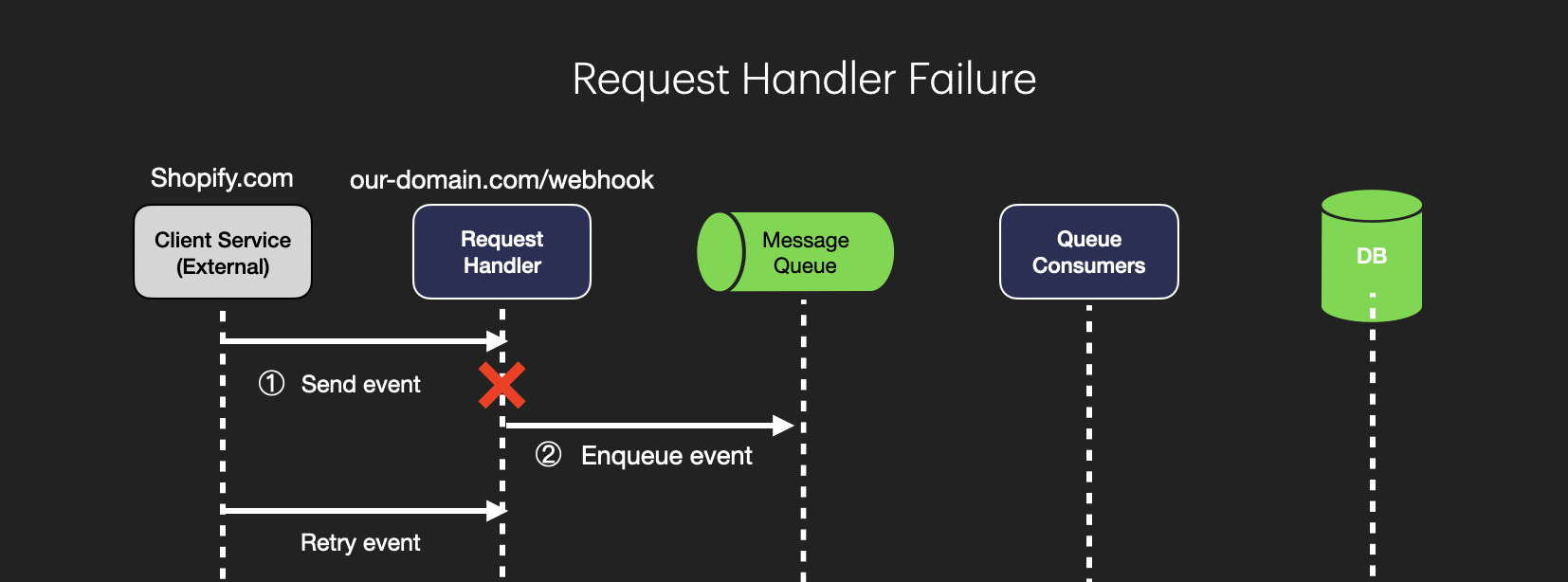
Failure Before Enqueuing: If the request handler fails after receiving an event but before it has enqueued the event in the message queue, the client service will not receive an HTTP 200 response. In this design, returning a 200 status code signifies that the event has been accepted. If the response isn’t sent, the client service knows that the event wasn’t successfully received and can retry sending it.
Timeouts and Circuit Breakers: Implementing timeouts and circuit breakers can help prevent the request handler from hanging indefinitely if it encounters issues. If a request takes too long to process, a timeout triggers a failure, signaling to the client to retry. A circuit breaker can temporarily halt request processing if failures are detected, giving the system time to recover.
2. Message Queue Failures
The message queue temporarily holds incoming events until they can be processed by queue consumers. Failures at this stage could result in lost events, which would undermine the system’s reliability. To prevent this, the following strategies are essential:
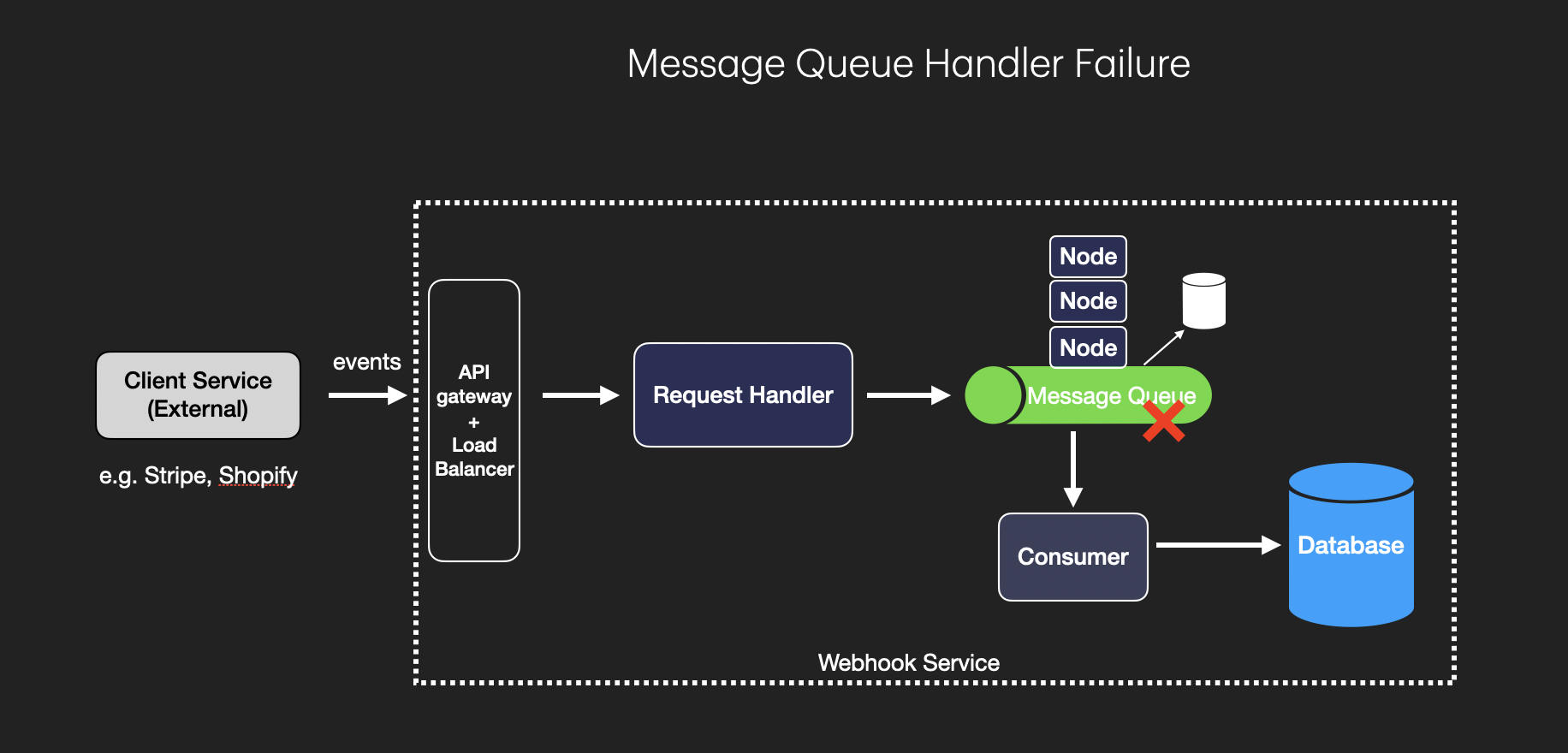
Durable Queues: Use durable queues that persist messages to disk. This ensures that, even if the queue server crashes or restarts, the events will still be available when the server comes back online. Durable queues typically store messages in a database or on disk rather than in memory, providing an extra layer of reliability.
Replication Across Multiple Nodes: By replicating the queue across multiple nodes, you can achieve high availability. If one node fails, other nodes can take over and continue processing events. Many message queue systems, such as Kafka and RabbitMQ, support cluster setups where messages are replicated across nodes to prevent data loss.
3. Queue Consumer Failures
Queue consumers fetch events from the message queue, process them, and then store the results. If a queue consumer fails mid-processing, this can lead to unacknowledged or incomplete operations. Here’s how to handle these failures:
Multiple Consumer Instances: Deploy multiple instances of queue consumers to ensure that, if one consumer fails, another can take over its workload. This setup provides fault tolerance and ensures continuous processing, especially during high-traffic periods.
Message Acknowledgment: Only acknowledge and dequeue a message after the event has been successfully processed and stored in the database. This guarantees that, if a consumer fails mid-processing, the message remains in the queue and can be retried by another consumer instance.
Auto-Restart and Scaling: Configure the system to automatically restart failed consumer instances. Many container orchestration platforms like Kubernetes can handle this automatically, ensuring that failed consumers are restarted promptly. Additionally, scaling consumer instances up or down based on queue length can help manage fluctuations in event volume. This is the primary reason why we use a message queue in the design.
4. Database Failures
Database failures are prevented using typical measures:
Write Retries with Backoff: Implement automatic retries with exponential backoff for database writes. If the first write attempt fails, the system retries after a short delay, with each subsequent delay increasing if failures continue. This helps avoid overwhelming the database during transient issues.
Database Replication and Failover: Use a database with built-in replication and failover capabilities. This allows the system to switch to a secondary database instance if the primary instance fails, minimizing downtime.
Additionally, standard monitoring and alerting practices should be implemented on all components (Request Handler, Message Queue, Queue Consumers, and Database) to detect issues like increased latency, high error rates, or resource bottlenecks. Use tools like Prometheus, Grafana, or New Relic to monitor key performance metrics and set up alerts for quick response.
Deep Dive Questions
How to secure the webhook service?
1. HMAC Signatures
The webhook provider (e.g., Stripe) and the webhook service share a secret key. The provider generates an HMAC hash of the payload using this secret and includes it in the request headers.
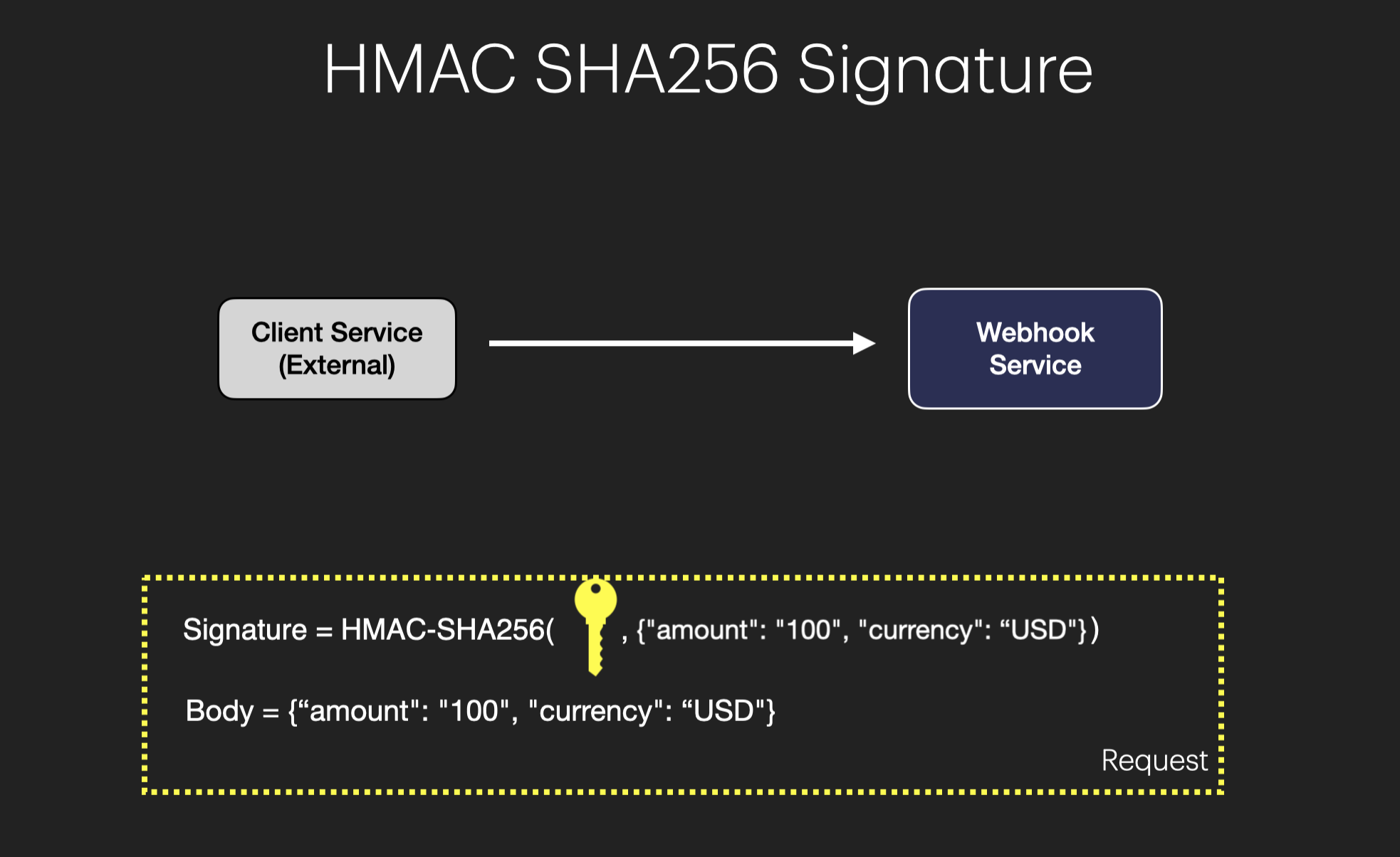
Verification: When the webhook service receives a request, it recalculates the HMAC hash using the shared secret and the request body. If the calculated hash matches the one in the request, the request is authenticated.
Benefit: Prevents unauthorized parties from spoofing requests, as they wouldn’t have the shared secret.
2. IP Whitelisting
Configure the webhook service to accept requests only from known IP addresses associated with the webhook provider. Many cloud providers offer firewall or network rules to allow traffic only from specific IP addresses.
Benefit: Protects against attacks from unauthorized IPs, reducing the attack surface. Although this requires the IP address of the webhook provider to not change.
3. Rate Limiting
Limit the number of requests the webhook service can accept from a specific IP or client within a certain time frame. For example, allow only 100 requests per minute per client.
Benefit: Prevents malicious actors from overwhelming the service by sending excessive requests (Denial-of-Service attacks, aka DoS attacks).
How to handle duplicate requests?
Duplicate webhook requests can occur due to network retries, client-side issues, or intentional replay attacks. It’s essential to design the webhook service to handle these duplicates gracefully to ensure data consistency and idempotent operations.
1. Idempotency Keys
An idempotency key is a unique identifier associated with each request that allows the server to recognize subsequent retries of the same request. To implement this, the webhook provider includes a unique identifier (e.g., event_id or request_id) in the webhook payload or headers. When processing a webhook event, store the event_id along with a timestamp in a dedicated database table for tracking processed events. Before processing a new event, check if the event_id already exists in the database; if it does, skip processing to prevent duplicate operations. Since we need to store events for 30 days, ensure that the idempotency keys are retained for at least the same duration to handle late-arriving duplicates.
2. Message Queue Deduplication
Some message queue systems offer built-in deduplication features based on message IDs (e.g., AWS SQS with deduplication). To utilize this, assign a unique message ID to each event when enqueuing it in the message queue. Configure the deduplication window according to the expected time frame in which duplicates might arrive. This setup prevents duplicate messages from being processed by consumers, reducing the load on the processing system.
How to handle out-of-order requests?
Out-of-order requests occur when events arrive at the webhook service in a different order than they were sent. This can happen due to factors likenetwork delays. For example, imagine we are building a system to process payment events from Stripe. If the Stripe sends two events:
invoice.paidinvoice.created
In an ideal world, we should process the invoice.created event first and then the invoice.paid event. However, this doesn't always happen and we may receive the invoice.paid event first. Our processing logic shouldn't expect these events to arrive in order and should be designed to handle them correctly.
To handle the invoice.paid event correctly, we can:
- Fetch the latest invoice data using Stripe API and the invoice ID provided in the
invoice.paidevent. This ensures you have the most up-to-date and complete invoice information before processing the payment status. - Update our local database with the latest invoice data, and update the invoice status to PAID. Then trigger any business logic that needs to happen when an invoice is paid.
When the invoice.created event arrives, we can:
- Compare the
created_timein theinvoice.createdevent with theupdated_timein theinvoice.paidevent. Once we realize this event is older than our current invoice data, we can skip processing it.
The takeaways are:
- Our system should not make assumptions about the order of events and our system's correctness does not depend on event order or uniqueness.
- Webhook should be designed to be idempotent and stateless.
To do that, we can:
- Use states from the source of truth (e.g., Stripe API) and avoid making assumptions about using local database states.
- Utilize event IDs and timestamps to determine if an event is outdated and should be skipped.





