Google Maps System Design
Designing a mapping service like Google Maps is a complex task that involves integrating massive amounts of multi-source data and processing real-time updates. The service should be able to load specified areas' streets and buildings, display real-time traffic conditions, search for streets, buildings, and landmarks, and plan navigation routes (providing both the shortest and fastest routes).
Functional Requirements
- Real-Time Traffic Information: The service should provide real-time traffic information and adjust routes based on traffic conditions.
- Route Planning: Given a starting point and a destination, the service should be able to calculate both the shortest and the fastest route (with the least time taken).
- Map Rendering: Refer to Design Map Rendering Service for reference.
- Geo-based Search: Refer to Yelp System Design.
Non-Functional Requirements
- 100M Daily Active Users
- Read:write ratio = 1000: 1
- Data retention for 5 years
- High availability
- Low latency
- High durability
- Security
Resource Estimation
Assuming an average usage of 30 minutes per user per day, with a read request made every 5 seconds, the service is expected to handle significantly more read requests. Given this usage pattern, each user would make approximately 360 read requests daily. This translates to approximately 4,166,667 read requests and 41,667 write requests per second.
The storage requirement, considering that each entry is 1KB and data is retained for 5 years, is approximately 6 PB.
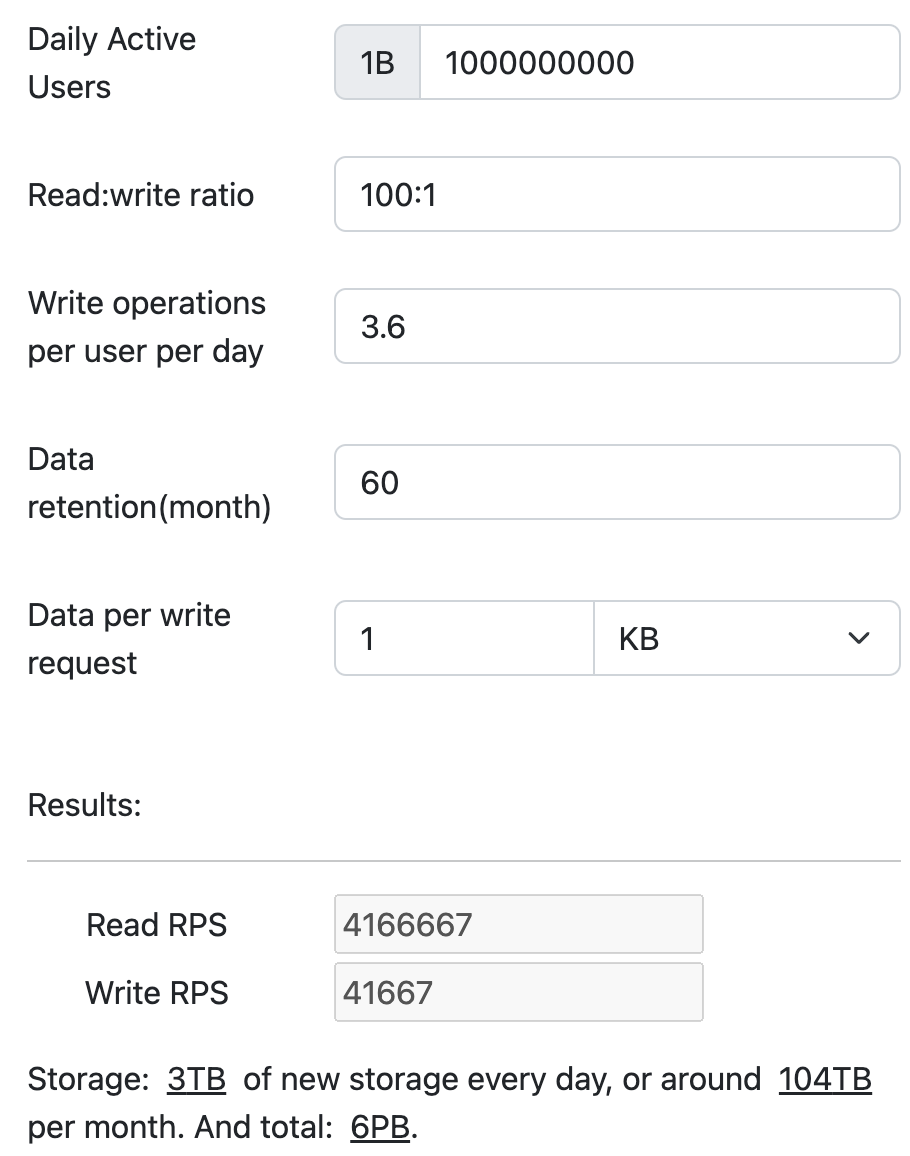

Use the resource estimator to calculate.
API Endpoint Design
- The client needs to frequently send real-time locations to the server. Considering the frequency, we use Websocket to implement:
ws://location, the message is in JSON format:
{
"lon": // Longitude coordinate, double, -180.0 ~ 180.0
"lat": // Latitude coordinate, double, -90.0 ~ 90.0
}/route?src_lon={source longitude}&src_lat={source latitude}&dst_lon={destination longitude}&dst_lat={destination latitude}, specify the longitude and latitude of the starting point and destination to provide the shortest and fastest routes. The response body is as follows:
{
"shortestPath": {
"description": "The path with the shortest distance",
"distance": "The specific distance value",
"duration": "The specific time value",
"path": [
{
"lon": // double
"lat": // double
},
...
]
},
"fastestPath": {
"description": "The path with the shortest time taken",
"distance": "The specific distance value",
"duration": "The specific time value",
"path": [
{
"lon": // double
"lat": // double
},
...
]
}
}High-Level Design
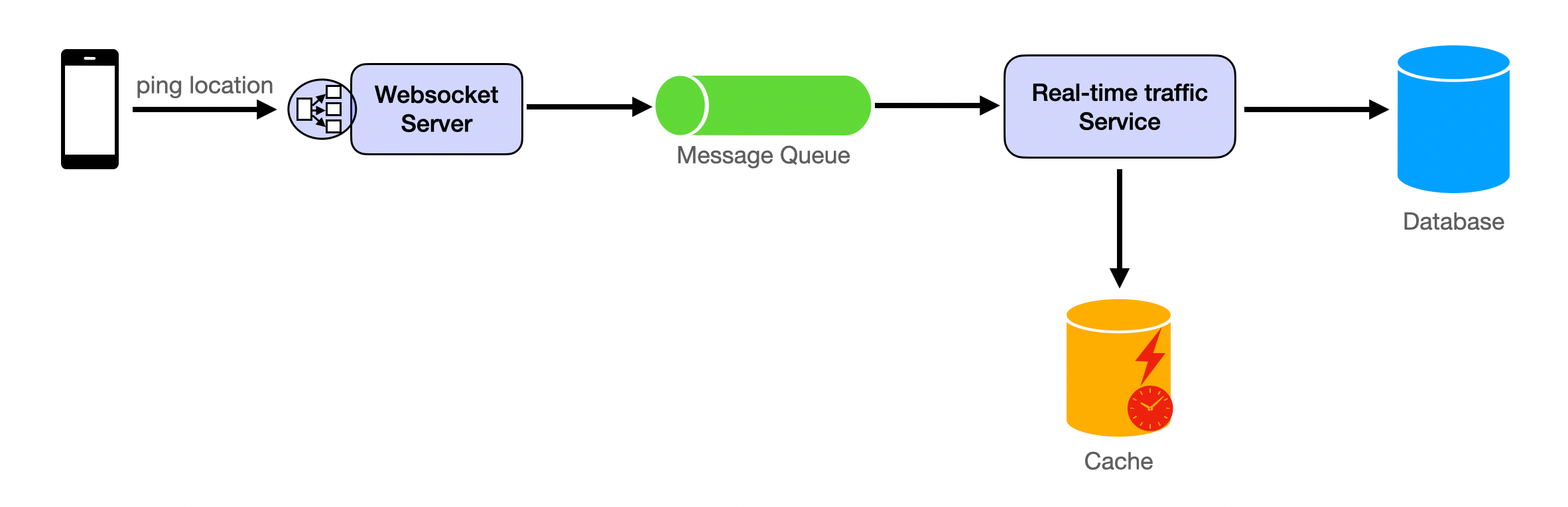
Real-time traffic conditions and the calculation of the shortest time for navigation both require the user's real-time location. This is the data that is updated most frequently. The client maintains a websocket connection, periodically sending location information to the server. Upon receiving the data, the Websocket Server writes the location information into the Message Queue. The Real-time traffic Service reads the location information from the Message Queue, saves the information to the database, and analyzes it. The traffic conditions derived from the analysis are written into the cache.
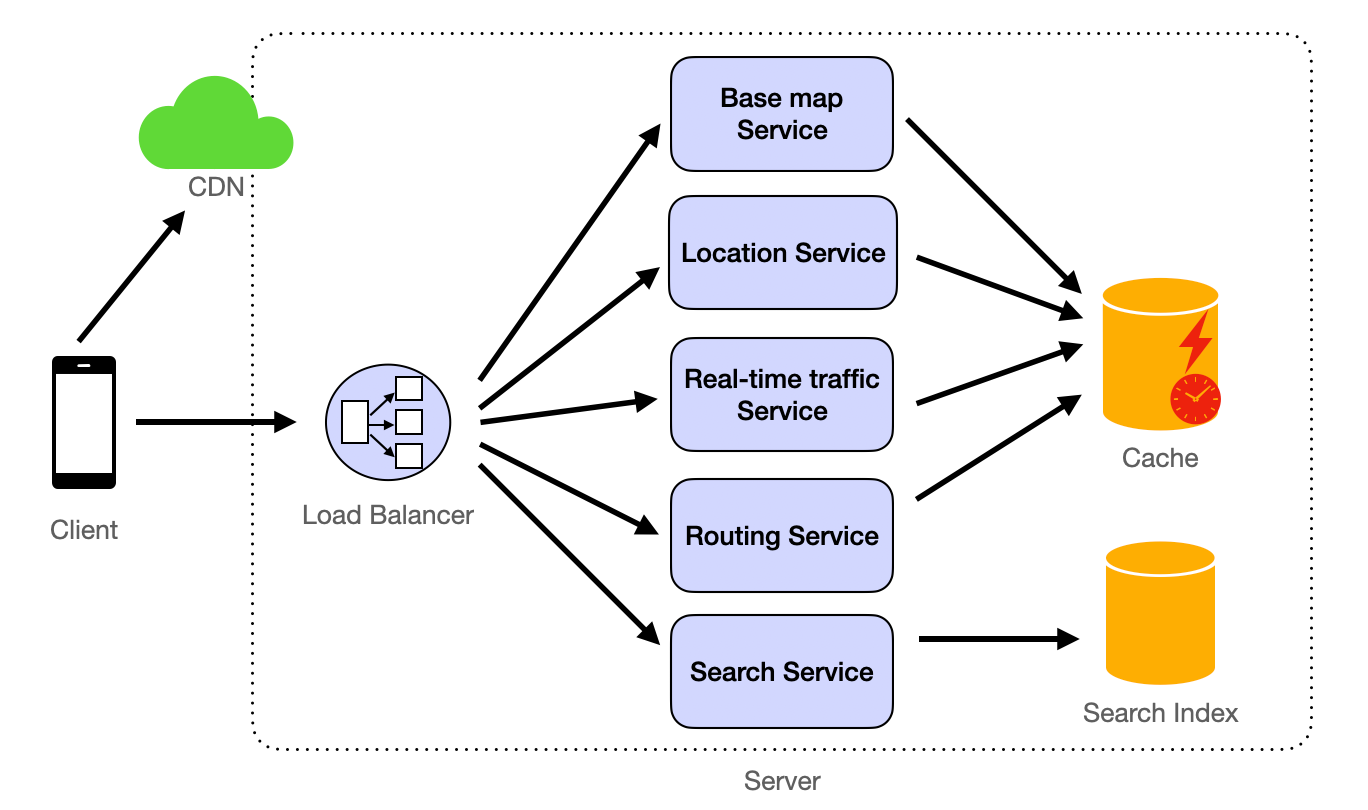
When the client loads the map, it first needs to render the underlying maps (referring to Design Map Rendering Service for details), which depict basic shapes such as some roads, buildings (outlines), bodies of water, and green spaces.
Real-time traffic information is loaded through the Real-time traffic Service.
When users perform a search, the Search Service searches for location information in the Search Index. Refer to Yelp System Design for details.
The Routing Service implements the navigation feature, analyzing the shortest and fastest routes based on the user's provided starting point and destination.
Detailed Design
Data Store
Database Type
For a service like Google Maps, we need a combination of database types to handle different kinds of data efficiently:
- Spatial Database: To store and query data related to locations and geographic information. Examples include PostGIS (an extension of PostgreSQL) and Google's proprietary solutions.
- NoSQL Database: For scalable, high-performance storage of unstructured data, such as real-time traffic conditions. Examples include Cassandra or MongoDB.
- Time-Series Database: To handle time-dependent data like historical traffic patterns, which can be used for predicting future conditions. Examples include InfluxDB.
- Graph Database: To store and compute the shortest/fastest paths efficiently. Examples include Neo4j.
Data Schema
- Map Data:
MapTile(id, northEastBound, southWestBound, imageUrls, lastUpdated)Landmark(id, name, location, type)Road(id, name, type, coordinates, trafficCondition)
- User Data:
User(id, username, hashedPassword, preferences)UserLocation(userId, timestamp, location)
- Traffic Data:
TrafficSnapshot(timestamp, roadId, trafficSpeed, trafficCondition)
Database Partitioning (Sharding)
Database partitioning is critical, and here's how we can approach partitioning the different types of data:
-
Geographic Partitioning (Sharding): The map data can be partitioned based on geographic boundaries. For example, the world can be divided into regions such as North America, Europe, Asia, etc., and each region's data is stored on separate database clusters. Within each region, further partitioning can occur at the country or city level.
- Fields for Partitioning:
MapTile: Partitioned bynorthEastBoundandsouthWestBoundcoordinates, which define the bounding box of the map tile.Landmark: Partitioned bylocation, which includes latitude and longitude.Road: Partitioned bycoordinates, which is an array of latitude and longitude pairs that define the road's path.
- Fields for Partitioning:
-
Functional Partitioning: Different types of data are stored in different databases optimized for their access patterns.
-
User Data:
User: Can be partitioned byidif the user base is large enough, with IDs hashed to distribute across shards evenly.UserLocation: Partitioned byuserIdto keep all location updates for a user on the same shard, enabling efficient query patterns for individual user history.
-
Traffic Data:
TrafficSnapshot: Partitioned bytimestampandroadId. Thetimestampallows for partitioning data into time-based chunks (e.g., per day or per hour), whileroadIdensures that all traffic data for a specific road segment is stored together.
-
For more detailed content, refer to Partitioning (Sharding).
Database Replication
- Read Replicas: To handle the high read load and improve read performance.
- Multi-Region Replication: To ensure low latency access across different geographical locations and provide disaster recovery.
For more information about replication, you can refer to the article Replication.
Data Retention and Cleanup
- Old Traffic Data: Aggregate and anonymize old traffic data for historical analysis and delete individual records after a certain period.
- User Data: Implement GDPR-compliant data retention policies, allowing users to request data deletion.
Cache
-
In-memory Data Stores:
Utilize in-memory data stores like Redis or Memcached to cache frequently accessed data. This includes:
- Map Tiles: Cache the most commonly requested map tiles at various zoom levels to speed up map loading times. Each tile can be identified by a unique key based on its geographic coordinates and zoom level.
- Search Results: Cache the results of common search queries, such as popular landmarks or addresses, to provide instant responses to repeat searches.
- User Sessions: Store session data, including user preferences and recent searches, to personalize the user experience without querying the database repeatedly.
-
Local Caching:
Implement local caching on the client side (e.g., mobile apps, web browsers) to store recently viewed map tiles and search results. This reduces redundant network requests and improves the user experience, especially in areas with poor connectivity.
-
Cache Invalidation:
Implement a robust cache invalidation strategy to ensure that users always receive the most up-to-date information. This includes:
- Time-based Expiration: Set a time-to-live (TTL) for each cached item, after which it is automatically refreshed from the source data.
- Event-driven Invalidation: Invalidate cache entries when underlying data changes, such as when a new road is added to the map or when traffic conditions change.
For additional information on caching, please refer to our article on Caching.
The usage of CDN
A Content Delivery Network (CDN) is extensively used to serve static assets like icons, stylesheets, and scripts. By caching these assets at edge locations around the world, the CDN reduces latency for end-users and decreases the load on the origin servers.
Analytics
For the analysis of large datasets, such as traffic patterns and map usage statistics, big data processing tools like Apache Hadoop and Spark are employed. These tools are designed to handle the processing of massive amounts of data efficiently. For real-time analytics, technologies such as Apache Kafka and Apache Flink are used to process data streams as they come in, enabling immediate insights into current traffic conditions and other dynamic data points. These analytics capabilities are crucial for making data-driven decisions and improving the overall service.
Real-time Traffic Service
The Real-time Traffic Service is responsible for processing and providing up-to-date traffic information to users. This service must handle a continuous stream of data from various sources, including user devices, sensors, and third-party feeds.
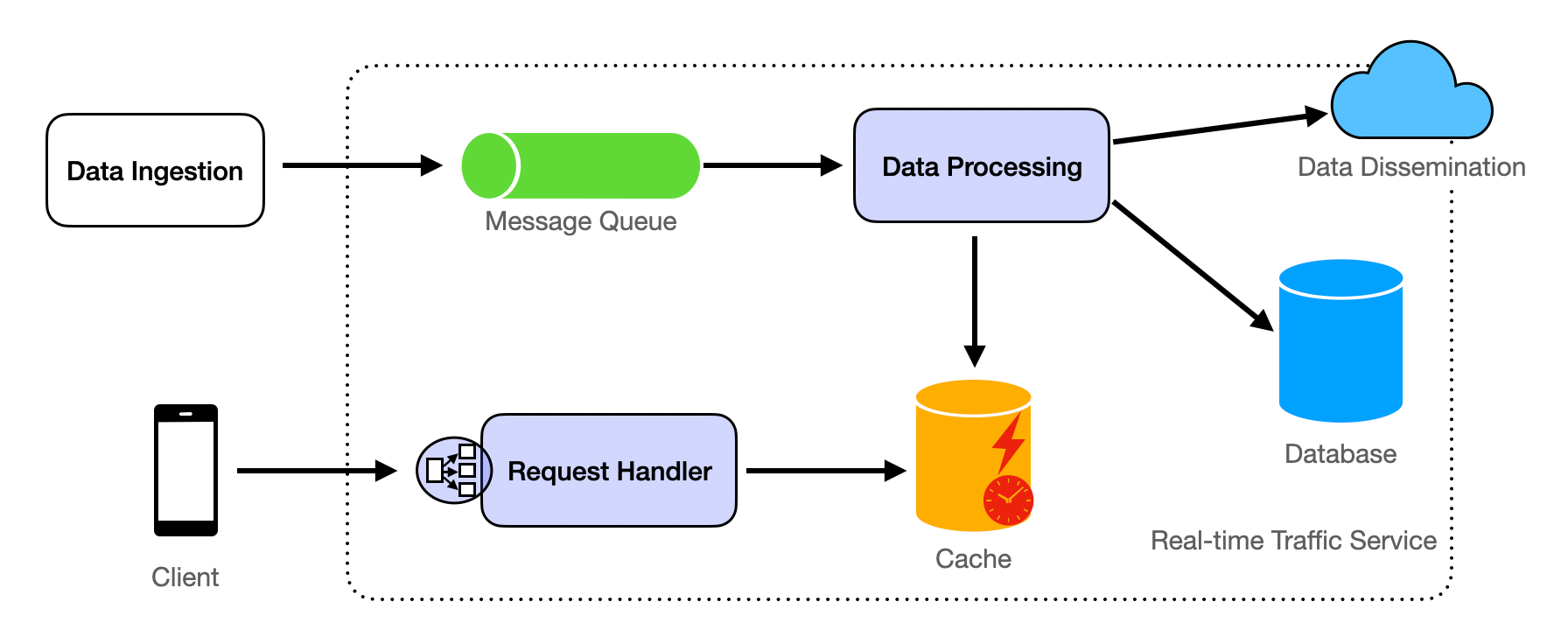
Key Components:
-
Data Ingestion: Real-time traffic data is ingested from multiple sources, including:
- User location updates from the Websocket Server.
- Traffic sensors and cameras deployed on roads.
- Third-party data providers offering traffic updates.
-
Data Processing:
The Data Processing component reads real-time traffic data from the Message Queue and stores it in the Database. For data analytics, it is necessary to analyze the current traffic conditions and travel times for each
Road. Subsequently, the analyzed data is updated in the cache.- Stream Processing: Utilize a stream processing framework such as Apache Kafka Streams or Apache Flink to handle incoming traffic data in real-time. Refer to the stream processing section for more details.
- Traffic Pattern Analysis: Implement machine learning algorithms to identify anomalies, forecast traffic congestion, and calculate travel times.
- Aggregation: Compile data over specific time intervals to provide a snapshot of the current traffic conditions.
-
Data Storage:
- Store processed traffic data in a time-series database for historical analysis and real-time access.
- Use a spatial database to correlate traffic data with specific road segments.
-
Data Dissemination:
- Push notifications to inform users about traffic incidents or congestions.
- Update map overlays with color-coded traffic conditions.
-
Request Handler:
- Provide RESTful APIs for clients to access real-time traffic information.
- Support filtering by geographic area, road segments, or user preferences.
Routing Service
Grasping the building blocks ("the lego pieces")
This part of the guide will focus on the various components that are often used to construct a system (the building blocks), and the design templates that provide a framework for structuring these blocks.
Core Building blocks
At the bare minimum you should know the core building blocks of system design
- Scaling stateless services with load balancing
- Scaling database reads with replication and caching
- Scaling database writes with partition (aka sharding)
- Scaling data flow with message queues
System Design Template
With these building blocks, you will be able to apply our template to solve many system design problems. We will dive into the details in the Design Template section. Here’s a sneak peak:
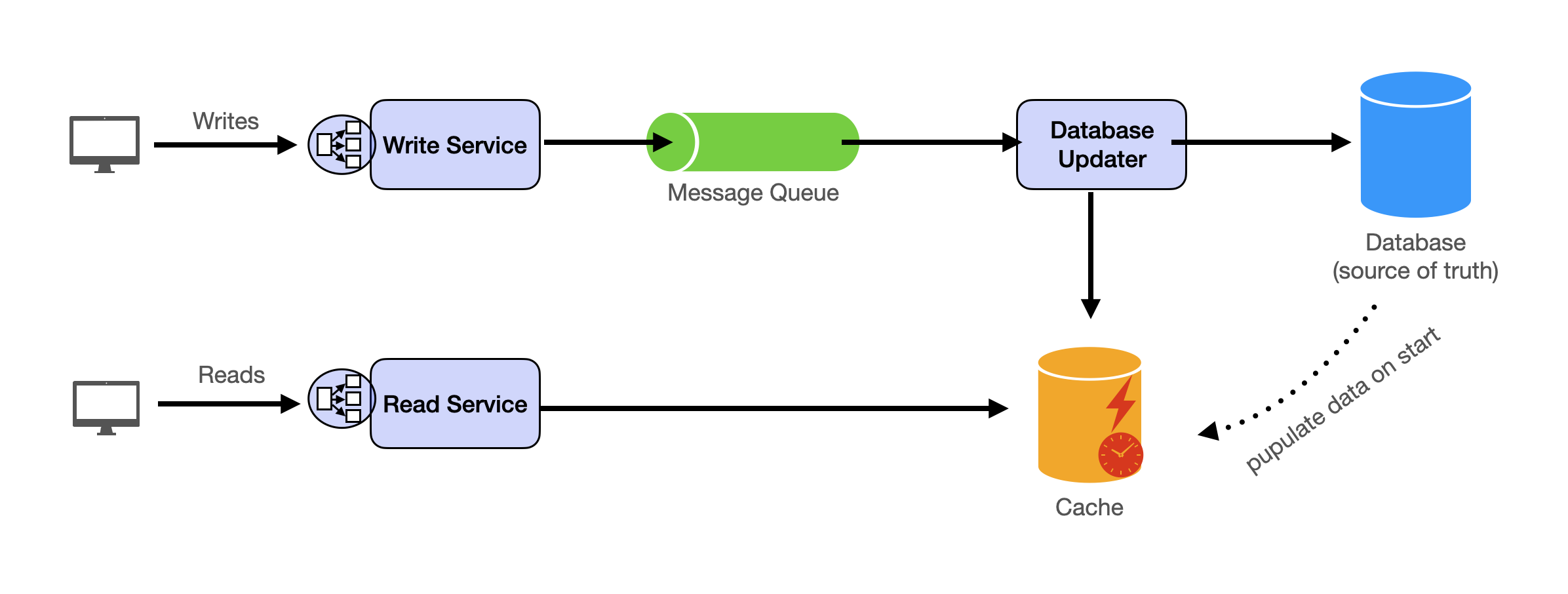
Additional Building Blocks
Additionally, you will want to understand these concepts
- Processing large amount of data (aka “big data”) with batch and stream processing
- Particularly useful for solving data-intensive problems such as designing an analytics app
- Achieving consistency across services using distribution transaction or event sourcing
- Particularly useful for solving problems that require strict transactions such as designing financial apps
- Full text search: full-text index
- Storing data for the long term: data warehousing
On top of these, there are ad hoc knowledge you would want to know tailored to certain problems. For example, geohashing for designing location-based services like Yelp or Uber, operational transform to solve problems like designing Google Doc. You can learn these these on a case-by-case basis. System design interviews are supposed to test your general design skills and not specific knowledge.
Working through problems and building solutions using the building blocks
Finally, we have a series of practical problems for you to work through. You can find the problem in /problems. This hands-on practice will not only help you apply the principles learned but will also enhance your understanding of how to use the building blocks to construct effective solutions. The list of questions grow. We are actively adding more questions to the list.