We aim to design a simplified version of Twitter, a popular social media platform where users can post tweets, follow or unfollow other users, and view the tweets of the people they follow. The platform also includes a recommendation algorithm that suggests content to users based on their preferences and interactions.
Functional Requirements
- Tweeting: Users should be able to write and post new tweets.
- Follow/Unfollow: Users should have the ability to follow or unfollow other users.
- Timeline: Users should be able to view a list of tweets from the people they follow, as well as content recommended by the recommendation algorithm.
Non-Functional Requirements
- 300M DAUs
- Each tweet is approximately 140 characters (or 280 bytes)
- Retain data for five years.
- Assuming each user posts one tweet per day.
- High availability
- Low latency
- High durability
- Security
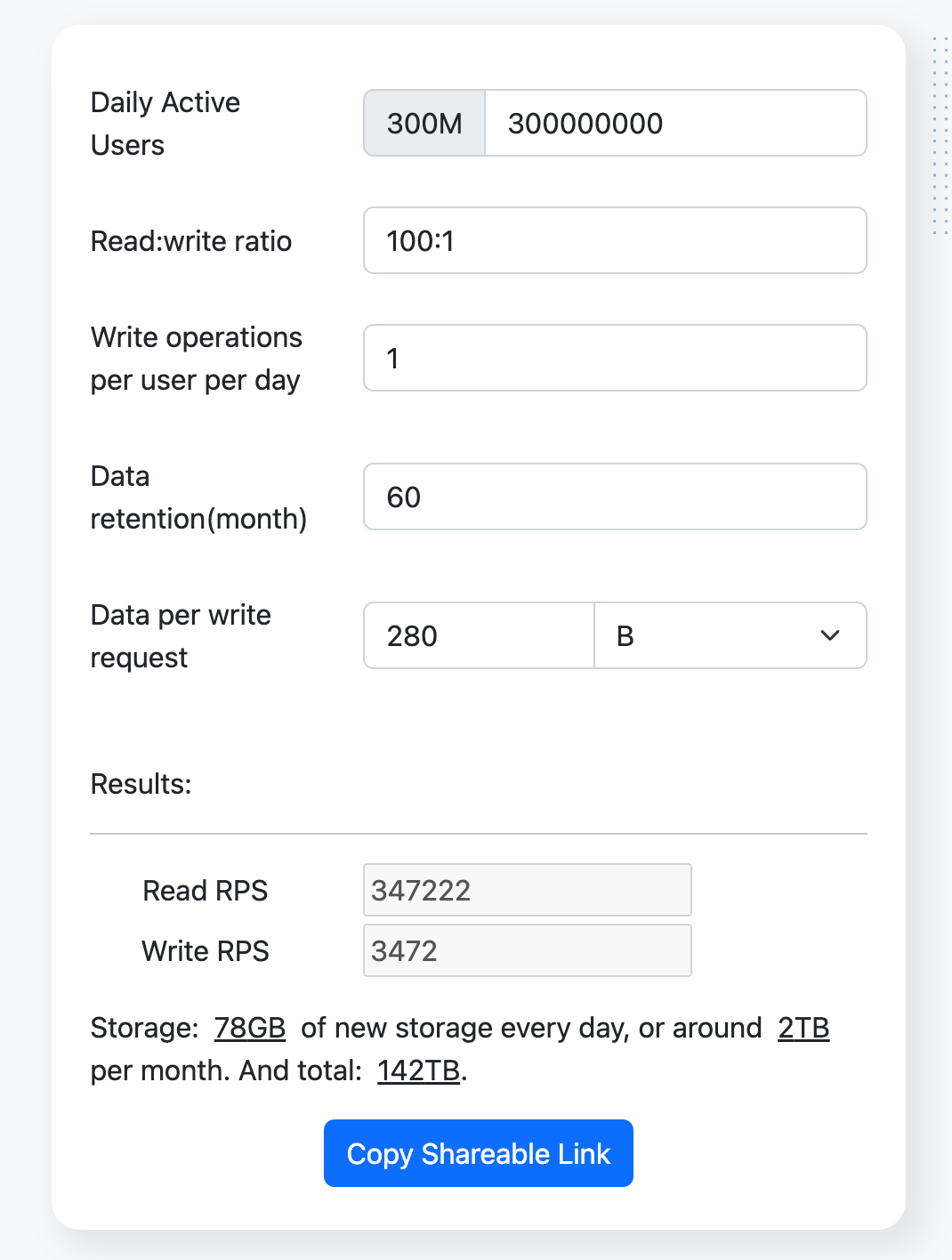
Resource Estimation
Assuming a read-write ratio of 100:1.
Using the resource estimator, we get the following results:

API Endpoint Design
The API endpoints could include:
POST /tweetsfor creating a new tweet. Request body as below:{ "content": "The content of the new tweet." }GET /tweets/{userId}?last={timestamp}&size={size}for retrieving a user's tweets.POST /follow/{userId}for following a user.DELETE /follow/{userId}for unfollowing a user.GET /timeline?last={timestamp}for retrieving timeline tweets.
High-Level Design
Twitter is the perfect example of designing scalable system using our system design template.
The system could be designed with distinct components, specifically the Tweet Service, Follow Service, and Timeline Service. The Design Diagram is as below:
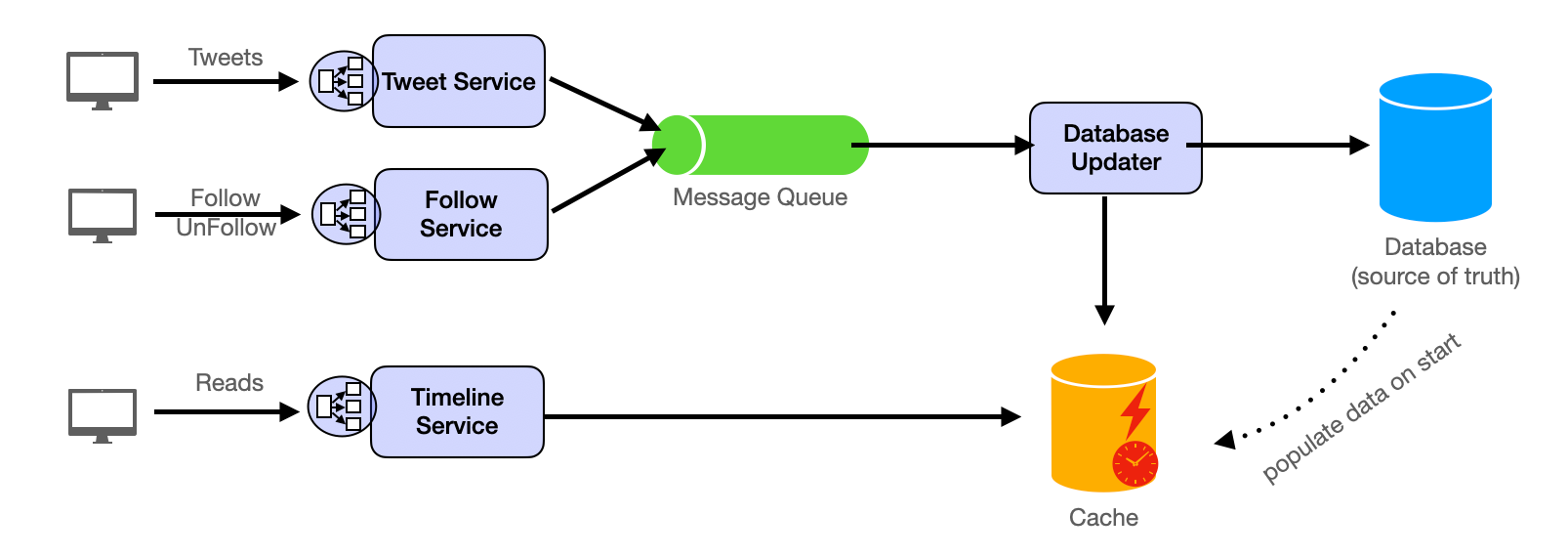
The Tweet Service and Follow Service are used to handle requests for sending tweets, following, and unfollowing. Considering the need for response speed to the client and support for high concurrency, these two services do not directly write into the database, but write the request data into the Message Queue. The Database Updater component reads the request data from the Message Queue, genuinely processes the business logic, writes into the server, and updates the cache.
The Timeline Service is used to handle requests for loading Twitter lists. Based on considerations of response speed and improving system efficiency, this service reads data from the cache, rather than accessing the database.
Fan-out-on-write
Each user has their own "inbox" inside the cache that stores the tweets to be displayed in its timeline. When a user it follows posts a tweet, the tweet is sent to its "inbox". This is often called "fan-out-on-write" because it replicates ("fans out") a piece of information to multiple destinations at the time of its creation or update. The advantage of this is it significantly enhances the read performance since the tweets are already present in a timeline cache when a user logs in. It reduces the need for complex and time-consuming queries at the time of read. However, for celebrities with millions of followings this could present a problem as the write would be quite large. This is a common follow-up question in Design Twitter interviews. We will cover it in the follow-up question section.
Detailed Design
Database Type
Considering the scale requirement of 300M DAU and assuming that each user sends one tweet per day, this would generate 300M tweets per day, which is a tremendous amount of data. At the same time, this system does not have complex query requirements. Considering these two points, NoSQL could be used as the database.
A NoSQL database like Cassandra could be used due to its ability to handle large amounts of data and its high write speed.
Data Schema
Grasping the building blocks ("the lego pieces")
This part of the guide will focus on the various components that are often used to construct a system (the building blocks), and the design templates that provide a framework for structuring these blocks.
Core Building blocks
At the bare minimum you should know the core building blocks of system design
- Scaling stateless services with load balancing
- Scaling database reads with replication and caching
- Scaling database writes with partition (aka sharding)
- Scaling data flow with message queues
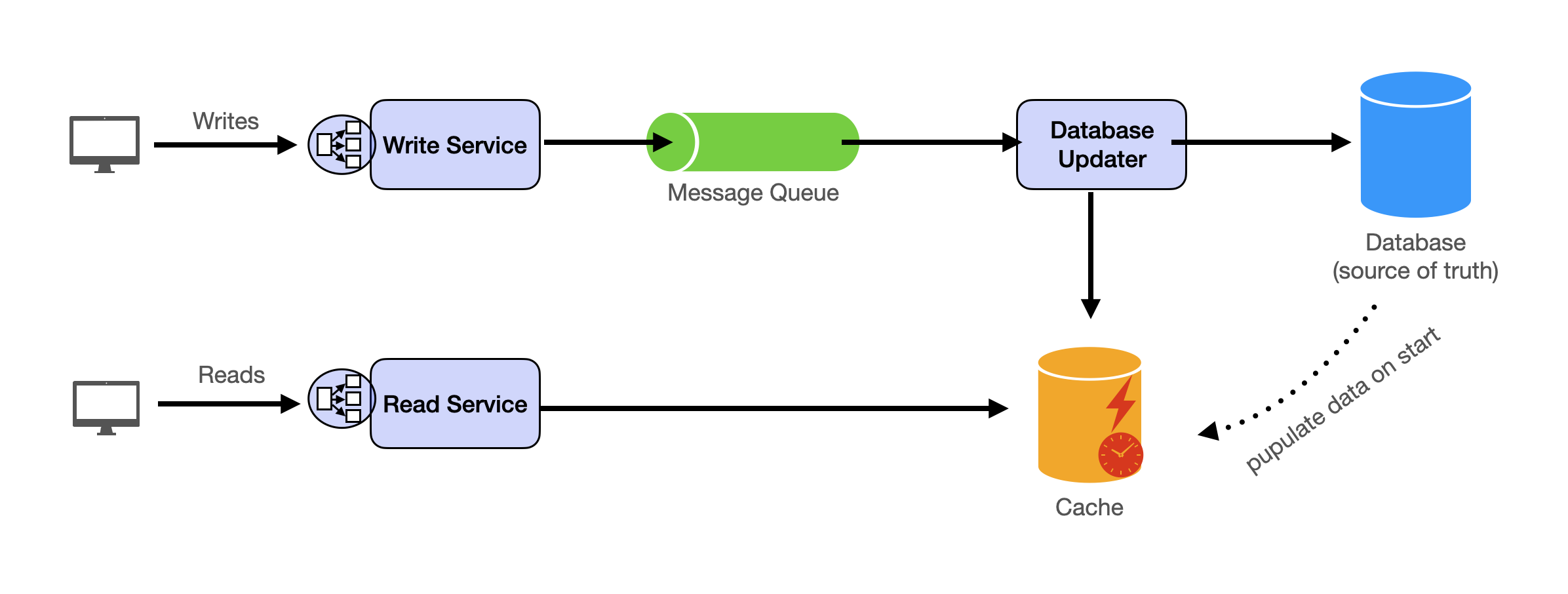
System Design Template
With these building blocks, you will be able to apply our template to solve many system design problems. We will dive into the details in the Design Template section. Here’s a sneak peak:
Additional Building Blocks
Additionally, you will want to understand these concepts
- Processing large amount of data (aka “big data”) with batch and stream processing
- Particularly useful for solving data-intensive problems such as designing an analytics app
- Achieving consistency across services using distribution transaction or event sourcing
- Particularly useful for solving problems that require strict transactions such as designing financial apps
- Full text search: full-text index
- Storing data for the long term: data warehousing
On top of these, there are ad hoc knowledge you would want to know tailored to certain problems. For example, geohashing for designing location-based services like Yelp or Uber, operational transform to solve problems like designing Google Doc. You can learn these these on a case-by-case basis. System design interviews are supposed to test your general design skills and not specific knowledge.
Working through problems and building solutions using the building blocks
Finally, we have a series of practical problems for you to work through. You can find the problem in /problems. This hands-on practice will not only help you apply the principles learned but will also enhance your understanding of how to use the building blocks to construct effective solutions. The list of questions grow. We are actively adding more questions to the list.




